
Algoritmos para Grafos | Índice
Este capítulo discute um algoritmo para do problema das componentes fortes (= strong components), que já foi apresentado no capítulo Componentes fortes.
Problema das componentes fortes: Encontrar as componentes fortes de um grafo.
Robert Tarjan descobriu (1972) um algoritmo muito eficiente para resolver o problema. Não por acaso, o algoritmo é semelhante ao que calcula as componentes aresta-biconexas de um grafo não-dirigido.
Sumário:
O algoritmo de Tarjan para o problema das componentes fortes é uma extensão do algoritmo de Tarjan para o problema da conexão forte, e portanto uma extensão da busca em profundidade. Antes de estudar o algoritmo, é preciso entender a relação entre as componentes fortes e as florestas DFS do grafo.
Durante uma busca DFS,
a cabeça
de uma componente forte é
o vértice da componente que tem o menor número de pré-ordem,
ou seja,
a cabeça é o primeiro vértice da componente
a ser descoberto pela busca.
Podemos dizer que a cabeça é a porta de entrada
da componente.
(Mas a cabeça não é uma propriedade intrínseca da componente,
já que diferentes buscas DFS
podem escolher diferentes cabeças.)
Segue da definição da busca DFS (veja a documentação da função dfsR()) que todos os vértices de uma componente forte são descendentes da cabeça da componente na floresta DFS. Além disso, se r é a cabeça de uma componente forte K então, para qualquer vértice x de K, todos os vértices do caminho que vai de r a x na floresta DFS pertencem a K. Essas duas propriedades podem ser resumidas assim:
Propriedade DFS das componentes fortes: Para qualquer floresta DFS de um grafo, a subfloresta induzida pelo conjunto de vértices de qualquer componente forte do grafo é uma árvore radicada.
Se removermos da floresta DFS os arcos que entram nas cabeças de componentes fortes (há no máximo um arco desse tipo para cada cabeça), teremos uma coleção de árvores radicadas. De acordo com a propriedade acima, cada uma dessas árvores corresponde, exatamente, a uma componente forte do grafo.
0
/ \
/ \
1 6
/ \ / \
2 5 7 8
/ /
3 9
/
4
Exemplo A. Considere o grafo definido pelas listas de adjacência abaixo. Veja ao lado uma floresta DFS do grafo (você deve imaginar que todos os arcos da floresta estão dirigidos de cima para baixo na figura).
0: 1 6 1: 2 5 2: 1 3 3: 4 4: 3 5: 2 6: 7 8 7: 3 6 9 8: 7 9:
Os únicos arcos do grafo que não estão na figura são 2-1, 5-2, 4-3, 7-3, 7-6 e 8-7. Acrescente esses arcos à figura para constatar que o grafo tem cinco componentes fortes e que essas componentes são induzidas pelos seguintes conjuntos de vértices:
3 4 1 2 5 9 6 7 8 0
Observe que os vértices de cada um desses conjuntos não estão espalhados pela floresta, uns longe dos outros. Mais precisamente, a subfloresta induzida por cada um desses conjuntos de vértices é uma árvore radicada.
As cabeças das componentes são 3, 1, 9, 6 e 0 respectivamente. Note a maneira como a busca DFS percorre as cinco componentes: primeiro visita o único vértice da componente 0, depois visita alguns vértices da componente 1 2 5, depois os vértices da componente 3 4, depois outro vértice da componente 1 2 5, depois alguns vértices da componente 6 7 8, depois o vértice da componente 9, e finalmente o vértice restante da componente 6 7 8.
0-1 1-2 2-0 3-4 4-5 5-3 3-2 0-1 1-5 5-0 2-3 3-4 4-2 1-2 0-1 1-2 2-0 3-4 4-5 5-3 6-7 7-8 8-6 3-1 6-0 7-5 0-1 1-2 2-0 3-7 7-8 8-3 7-4 4-5 5-6 6-4 4-2
Considere a floresta DFS produzida por uma busca DFS num grafo. Sejam r0, r1, … , rn−1 as cabeças das componentes fortes do grafo. Suponha que essa lista de cabeças está em pós-ordem inversa. Assim, rn−1 é a primeira cabeça a morrer — ou seja, a primeira a terminar de ser processada pela função dfsR() — e r0 é a última.
Para cada i, seja Ki a componente forte cuja cabeça é ri. Não é difícil deduzir da propriedade DFS das componentes fortes que Kn−1 é induzida pelo conjunto de todos os descendentes de rn−1 na floresta DFS. Já Kn−2 é induzida pelo conjunto de descendentes de rn−2 que não estão em Kn−1. Da mesma forma, Kn−3 é induzida pelo conjunto de descendentes de rn−3 que não estão em Kn−1 ∪ Kn−2. Finalmente, K0 é induzida pelo conjunto de descendentes de r0 que não estão em Kn−1 ∪ … ∪ K1.
Essas observações são a base do algoritmo de Tarjan.
A principal dificuldade do algoritmo
é reconhecer as cabeças das componentes fortes, ou seja,
distinguir uma cabeça de um vértice comum
.
Não há como reconhecer uma cabeça no momento em que ela é descoberta pela busca DFS; é preciso esperar pelo momento em que a cabeça morre. Por isso será necessário armazenar, em algum vetor, todos os vértices descobertos durante o intervalo de vida da cabeça. Quando a cabeça for reconhecida como tal, os vértices da correspondente componente estarão todos no vetor. Se o vetor for administrado como uma pilha, poderá ser naturalmente compartilhado por todas as componentes. Quando um determinado vértice v da pilha for reconhecido como cabeça, todos os vértices da componente de v estarão armazenados acima de v na pilha, podendo então ser removidos da pilha e impressos. (Essa pilha é análoga à usada pelo algoritmo de Tarjan para componentes aresta-biconexas.)
Antes que possamos descrever o algoritmo é preciso caracterizar as cabeças de componentes por meio do conceito de abraço, definir uma numeração lo[] dos vértices, e finalmente estabelecer uma fórmula recursiva para lo[].
Para reconhecer uma cabeça de componente forte, o algoritmo de Tarjan usa o conceito de abraço. Dada uma floresta DFS de um grafo, diremos que um arco x-y do grafo abraça um vértice v da floresta se
(Em virtude da condição 3 da definição, esse conceito de abraço é bem mais restritivo que aquele usado pelo algoritmo que decide conexão forte no capítulo Grafos fortemente conexos.) A inexistência de abraços caracteriza as cabeças de componentes fortes, ou seja, fornece um critério para decidir se um dado vértice é uma cabeça.
Lema do abraço: Depois de uma busca DFS num grafo, um vértice v é cabeça de uma componente forte se e somente se nenhum arco do grafo abraça v.
Eis um esboço da prova do lema: Se um arco x-y abraça v, existe um passeio de v até algum ancestral próprio r de v. Como existe um caminho de r a v, os vértices r e v pertencem à mesma componente forte. Como r é diferente de v, esse último não é cabeça da componente.
À primeira vista, o critério fornecido pelo lema parece computacionalmente pesado: para cada vértice v, todos os arcos do grafo deveriam ser testados. Mas é possível organizar os cálculos de modo a testar cada arco uma única vez (no decurso de uma busca em profundidade). Para fazer isso, a próxima seção introduz o conceito de número de pré-ordem mínimo.
a
|
b
|
c
/ \
d g
/ \
e h
/
f
Exemplo B. Seja G o grafo com vértices a..h definido pelas listas de adjacência abaixo. Veja ao lado uma floresta DFS do grafo.
a: b b: c c: d g d: e e: b f f: d g: h h: f
Os únicos arcos do grafo que não estão na floresta são e-b, f-d, h-f. O arco e-b abraça os vértices e, d, c. O arco f-d abraça f bem como e. O arco h-f abraça g (veja o caminho f-d-e-b). O arco h-f também abraça h. Portanto, os vértices a e b são as únicas cabeças.
O lema do abraço oferece um critério para reconhecer cabeças de componentes fortes. Para que esse critério possa ser aplicado eficientemente, é preciso introduzir o seguinte conceito auxiliar. O número de pré-ordem mínimo (= lowest preorder number) de um vértice v é o número lo[v] assim definido:
lo[v] = minx-y pre[y]
sendo o mínimo tomado sobre todos os arcos x-y
que abraçam v.
(Muitos livros escrevem low
no lugar do meu lo
.)
Note que lo[v] < pre[v]
sempre que algum arco abraça v
(veja exercício acima).
Se nenhum arco abraça v
então, de acordo com a definição, lo[v] é infinito;
mas é mais conveniente adotar a definição especial lo[v] = pre[v]
nesse caso.
Desse modo, teremos lo[v] ≤ pre[v]
para todo vértice v sem exceção.
O lema do abraço pode agora ser reformulado em termos da numeração lo[]: Um vértice v é cabeça de uma componente forte se e somente se
lo[v] ≡ pre[v].
Essa reformulação haverá de permitir o reconhecimento eficiente de cabeças de componentes fortes.
0a0
|
1b1
|
2c1
/ \
3d1 6g5
/ \
4e1 7h5
/
5f3
Exemplo C. Considere novamente o grafo do exemplo B, definido pelas seguintes listas de adjacência:
a: b b: c c: d g d: e e: b f f: d g: h h: f
A figura à direita mostra uma floresta DFS do grafo em que cada vértice v é precedido pelo número pre[v] e seguido do número lo[v]. Lembre-se de que os únicos arcos do grafo que não estão na floresta são e-b, f-d e h-f. Confira os valores de lo[]!
Cálculo eficiente de lo[ ]. Para calcular lo[] eficientemente durante a busca DFS, usaremos a seguinte fórmula recursiva, que exprime o valor de lo[] em v em função dos valores que lo[] nos filhos de v. Para cada vértice v, lo[v] é o menor dentre os números dos seguintes tipos:
O primeiro e o segundo itens da fórmula podem ser vazios. Se ambos forem vazios então lo[v] = pre[v]. O segundo e o terceiro itens da fórmula constituem a base da recursão. A prova cuidadosa da fórmula é um bom exercício.
A fórmula recursiva calcula lo[] em pós-ordem: se a permutação dos vértices em pós-ordem é i, j, k, … então a fórmula calcula lo[i], depois lo[j], depois lo[k], e assim por diante. Podemos também usar o inverso da permutação em pré-ordem, uma vez que a fórmula só depende da relação entre pais e filhos na floresta DFS.
Infelizmente, a aplicação da fórmula tem uma dificuldade séria: no segundo item da fórmula, não está claro como verificar a condição 3 da definição de abraço, ou seja, como saber se existe um caminho que vai de w até um ancestral próprio de v. Enfrentaremos essa dificuldade na próxima seção.
grafo-ciclo0-1-2-3-4-5-6-7-8-9-0. Faça uma busca DFS a partir do vértice 0. Calcule a numeração lo[] diretamente a partir da definição.
grafo-caminho0-1-2-3-4-5-6-7-8-9. Faça uma busca DFS a partir do vértice 0. Calcule a numeração lo[] diretamente a partir da definição.
trevo de 3 folhasdefinido pelos arcos 0-1 1-0 1-2 2-1 1-3 3-2. Calcule a numeração lo[] diretamente a partir da definição.
A discussão precedende —
cabeças, abraços, numeração lo[] —
leva à seguinte função GRAPHstrongCompsT()
que implementa o algoritmo de Tarjan.
(O sc
no nome
da função é uma abreviatura de strong component.)
A função recebe um grafo G,
calcula as componentes fortes do grafo,
e armazena num vetor sc[]
uma numeração dos vértices que
identifica as componentes.
/* A função GRAPHstrongCompsT() devolve o número de componentes fortes do grafo G e armazena no vetor sc[], indexado pelo vértices de G, os rótulos das componentes fortes de G: para cada vértice v, sc[v] será o rótulo da componente forte que contém v. Os rótulos são 0, 1, 2, etc. (A função implementa o algoritmo de Tarjan.) */
static int pre[1000], lo[1000]; static vertex stack[1000]; static int t, cnt, k;
int GRAPHstrongCompsT( Graph G, int *sc) { for (vertex v = 0; v < G->V; ++v) pre[v] = sc[v] = -1; t = cnt = k = 0; for (vertex v = 0; v < G->V; ++v) if (pre[v] == -1) dfsRstrongCompsT( G, v, sc); return k; }
A função dfsRstrongCompsT() executa uma busca DFS e administra uma pilha de vértices stack[0..t-1], com topo na posição t-1. Toda vez que descobre um novo vértice v, a função coloca v na pilha e calcula lo[v] usando a fórmula recursiva acima. Quando um vértice v morre (no sentido da busca DFS) a função usa o critério estabelecido acima para decidir se v é a cabeça de uma componente. Em caso afirmativo, todos os vértices da componente estão na pilha entre v e o topo da pilha. Nesse momento, todos esses vértices são removidos da pilha e recebem um mesmo rótulo em sc[].
/* A função dfsRstrongCompsT() visita todos os vértices de G que podem ser alcançados a partir do vértice v sem passar por vértices já descobertos. A função atribui cnt+k a pre[x] se x é o k-ésimo vértice descoberto e calcula o valor de lo[x] para cada vértice x descoberto. (O código foi adaptado da figura 5.15 do livro de Aho, Hopcroft e Ullman.) */
#define min( A, B) (A) < (B) ? (A) : (B) static void dfsRstrongCompsT( Graph G, vertex v, int *sc) { pre[v] = cnt++; stack[t++] = v; // A lo[v] = pre[v]; for (link a = G->adj[v]; a != NULL; a = a->next) { vertex w = a->w; if (pre[w] == -1) { // B dfsRstrongCompsT( G, w, sc); // calcula lo[w] // C lo[v] = min( lo[v], lo[w]); // D } else if (pre[w] < pre[v] && sc[w] == -1) { // E lo[v] = min( lo[v], pre[w]); // F } // G } // H if (lo[v] == pre[v]) { // v é uma cabeça vertex u; // I do { // J u = stack[--t]; sc[u] = k; } while (u != v); // K k++; } }
Resta esclarecer, com mais cuidado,
como a função usa a fórmula recursiva para calcular o valor de lo[v].
Os primeiro e terceiro itens da fórmula, bem como a parte
pre[w] < pre[v]
do segundo item,
são fáceis de verificar.
Mas a condição existe um caminho no grafo que vai de w
até um ancestral próprio de v
do segundo item é bem mais sutil.
Essa condição está satisfeita se w está na pilha,
como mostra a propriedade a seguir.
Propriedade da pilha de vértices: No início da execução da encarnação dfsRstrongCompsT(G,v) da função, cada vértice da pilha stack[0..t-1] é origem de um caminho no grafo que vai até um ancestral próprio de v.
(Eis um esboço da prova da propriedade: Considere o momento em dfsRstrongCompsT(G,v) começa a ser executada. Seja u um vértice da pilha e r a cabeça da componente forte que contém u. A encarnação dfsRstrongCompsT(G,r) certamente já nasceu mas ainda não morreu, pois do contrário r e u já teriam sido removidos da pilha. Logo, o intervalo de vida de dfsRstrongCompsT(G,r) contém o intervalo de vida de dfsRstrongCompsT(G,v), e portanto r é ancestral próprio de v.)
Para saber se w está na pilha, basta verificar se pre[v] já foi definido mas sc[w] ainda não foi definido. Ou seja, basta verificar se pre[w] ≠ -1 mas sc[w] ≡ -1.
Em resumo, o funcionamento de dfsRstrongCompsT() pode ser detalhado como segue. As linhas B a G do código aplicam a fórmula recursiva de lo[]. A linha D aplica o primeiro item da fórmula usando o valor de lo[w] que acabou de ser calculado na linha C. No fim da linha E temos pre[w] ≠ -1 e sc[w] ≡ -1, donde w está na pilha. Portanto existe um caminho de w até um ancestral próprio de v, donde o arco v-w abraça v. Assim, a linha F aplica o segundo item da fórmula.
a
|
b
|
c
/ \
d f
/
e
Exemplo D. Considere o grafo definido pelas listas de adjacência abaixo. Veja à direita uma floresta DFS do grafo.
a: b b: c c: d f d: e e: d f: b d
Veja o rastreamento da execução da função GRAPHstrongCompsT(),
com dfsR(v)
representando
dfsRstrongCompsT(G,v)
:
stack componentes
a dfsR(a) a
a-b dfsR(b) ab
b-c dfsR(c) abc
c-d dfsR(d) abcd
d-e dfsR(e) abcde
e-d
e (lo=3) abcde
d (lo=3) abc ed
c-f dfsR(f) abcf
f-b
f-d
f (lo=1) abcf
c (lo=1) abcf
b (lo=1) a fcb
a a
0a0
|
1b1
|
2c1
/ \
3d3 5f1
/
4e3
Na figura da floresta DFS à direita, cada vértice v é precedido do valor de pre[v] e seguido do valor de lo[v]. A figura mostra que as cabeças das componentes fortes são d, b, a.
Nas linhas do rastreamento que começam com um v dfsRstrongCompsT(v) ou um u-v dfsRstrongCompsT(v), a coluna stack dá o estado da pilha stack[0..t-1] no fim da linha A do código.
As linhas do rastreamento que têm apenas um v-w na primeira coluna representam o processamento do arco v-w pelo bloco de linhas E-G do código.
Cada linha do rastreamento que tem apenas um v (lo=i) na primeira coluna marca o fim do processamento do vértice v (fim da linha H do código). Nessa ocasião, i é o valor de lo[v]. A coluna stack dá o estado da pilha stack[0..t-1] no fim da execução de dfsRstrongCompsT(G,v,sc) e a coluna componentes dá os vértices da nova componente descoberta se lo[v] ≡ pre[v].
Ao fim da execução da função, os vetores pre[], lo[] e sc[] estarão no seguinte estado:
v a b c d e f
pre[v] 0 1 2 3 4 5
lo[v] 0 1 1 3 3 1
sc[v] 2 1 1 0 0 1
a
/ \
b c
\
d
\
e
Exemplo E. Considere o grafo definido pelas listas de adjacência abaixo. Veja à direita uma floresta DFS do grafo.
a: b c b: c: d e d: b e e: c
Veja o rastreamento da execução da função GRAPHstrongCompsT(),
com dfsR(v)
representando
dfsRstrongCompsT(G,v)
:
stack componentes
a dfsR(a) a
a-b dfsR(b) ab
b a b
a-c dfsR(c) ac
c-d dfsR(d) acd
d-b
d-e dfsR(e) acde
e-c
e-d
e acde
d (lo=2) acde
c-e
c (lo=2) a edc
a (lo=0) a
0a0
/ \
1b1 2c2
\
3d2
\
4e2
Na figura à direita, cada vértice v da floresta DFS é precedido do valor de pre[v] e seguido do valor de lo[v]. A figura mostra que as cabeças da componentes fortes são b, c, a. O vetor sc[] termina no seguinte estado:
v a b c d e sc[v] 0 1 2 3 4
a b
/ \
c d
\
e
Exemplo F. Considere a aplicação da função GRAPHstrongCompsT() ao grafo definido pelas listas de adjacência abaixo. Veja ao lado uma floresta DFS do grafo.
a: b: a c d c: a b d: e e: a c
Segue o rastreamento da execução de GRAPHstrongCompsT(),
com dfsR(v)
representando
dfsRstrongCompsT(G,v)
:
stack componentes
a dfsR(a) a
a (lo=0) a
b dfsR(b) b
b-a
b-c dfsR(c) bc
c-a
c-b
c (lo=1) bc
b-d dfsR(d) bcd
d-e dfsR(e) bcde
e-a
e-c
e (lo=2) bcde
d (lo=2) bcde
b (lo=1) edcb
0a0 1b1
/ \
2c1 3d2
\
4e2
Na figura à direita, cada vértice v da floresta DFS é precedido de pre[v] e seguido de lo[v]. A figura mostra que as cabeças da componentes fortes são b, c, a. O vetor sc[] termina no seguinte estado:
v a b c d e sc[v] 0 1 1 1 1
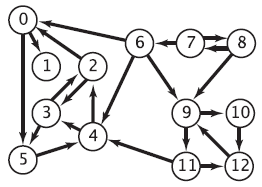
Exemplo G. Considere a aplicação da função GRAPHstrongCompsT() ao grafo da figura. Para que o exemplo seja mais legível, usaremos os seguintes nomes alfabéticos alternativos para os vértices:
0 1 2 3 4 5 6 7 8 9 10 11 12 a b c d e f g h i j k l m
Veja a seguir o rastreamento da execução da função supondo que as listas de adjacência estão em ordem crescente dos nomes dos vértices.
stack componentes
a dfsR(a) a
a-b dfsR(b) ab
b (lo=1) a b
a-f dfsR(f) af
f-e dfsR(e) afe
e-c dfsR(c) afec
c-a
c-d dfsR(d) afecd
d-c
d-f
d (lo=2) afecd
c (lo=0) afecd
e-d
e (lo=0) afecd
f (lo=0) afecd
a (lo=0) dcefa
g dfsR(g) g
g-a
g-e
g-j dfsR(j) gj
j-k dfsR(k) gjk
k-m dfsR(m) gjkm
m-j
m (lo=7) gjkm
k (lo=7) gjkm
j-l dfsR(l) gjkml
l-e
l-m
l (lo=9) gjkml
j (lo=7) g lmkj
g (lo=6) g
h dfsR(h) h
h-g
h-i dfsR(i) hi
i-h
i-j
i (lo=11) hi
h (lo=11) ih
0a0 6g6 11h11
/ \ | |
1b1 2f0 7j7 12i11
\ / \
3e0 8k7 10l9
\ /
4c0 9m7
\
5d2
Na figura à direita, cada vértice v da floresta DFS é precedido de pre[v] e seguido de lo[v]. A figura mostra que as cabeças da componentes fortes são b, a, j, g, h. Veja uma representação das componentes fortes na figura que está no início deste capítulo. Os vetores pre[], lo[] e sc[] terminam no seguinte estado:
v a b c d e f g h i j k l m
pre[v] 0 1 4 5 3 2 6 11 12 7 8 10 9
lo[v] 0 1 0 2 0 0 6 11 11 7 7 9 7
sc[v] 1 0 1 1 1 1 3 4 4 2 2 2 2
grafo-caminho0-1-2-3-4-5-6-7-8-9. Aplique a função GRAPHstrongCompsT() ao
grafo-ciclo0-1-2-3-4-5-6-7-8-9-0.
trevo de 3 folhasdefinido pelos arcos 0-1 1-0 1-2 2-1 1-3 3-2. Faça o rastreamento da execução da função.
static void dfsRstrongCompsT( Graph G, vertex v, int *sc) {
pre[v] = cnt++;
stack[t++] = v;
int min = pre[v];
for (link a = G->adj[v]; a != NULL; a = a->next) {
vertex w = a->w;
if (pre[w] == -1)
dfsRstrongCompsT( G, w, sc);
if (lo[w] < min) min = lo[w];
}
lo[v] = min;
if (lo[v] == pre[v]) {
vertex u;
do {
u = stack[--t];
sc[u] = k;
lo[u] = G->V;
} while (stack[t] != v);
k++;
}
}
A função GRAPHstrongCompsT() consiste essencialmente em uma busca em profundidade. Assim, o consumo de tempo é proporcional a
V + A
no pior caso, sendo V o número de vértices e A o número de arcos do grafo. (Se A ≥ V, como acontece em muitas aplicações, podemos dizer que o consumo de tempo é proporcional a A.) O algoritmo é, portanto, linear no tamanho do grafo.