Algoritmos para Grafos | Índice
Este capítulo discute o célebre algoritmo de Kruskal para o problema da MST. (O algoritmo foi publicado por Joseph Kruskal em 1956.)
Problema: Encontrar uma MST (árvore geradora de custo mínimo) de um grafo não-dirigido com custos nas arestas.
Os custos são números inteiros arbitrários (positivos e negativos). Os conceitos básicos relativos ao problema da MST podem ser vistos no capítulo geral sobre árvores geradoras de custo mínimo.
O problema tem solução se e somente se o grafo é conexo. Assim, vamos tratar apenas de grafos não-dirigido conexos. (Mas veja exercício abaixo.)
O algoritmo de Kruskal faz crescer uma floresta geradora até que ela se torne conexa. A floresta cresce de modo a satisfazer o critério de minimalidade de MSTs baseado em circuitos.
Para discutir os detalhes, precisamos de um pouco de terminologia. Uma subfloresta de um grafo não-dirigido G é qualquer floresta que seja subgrafo não-dirigido de G. Uma floresta geradora de G é qualquer subfloresta que tenha o mesmo conjunto de vértices que G.
Uma aresta a de G é externa a uma floresta geradora F se a não pertence a F e o grafo F + a é uma floresta, ou seja, um grafo sem circuitos. Portanto, uma aresta é externa a F se tem uma ponta em uma componente conexa de F e outra ponta em outra componente.
Podemos agora tratar do algoritmo.
![]() Cada iteração do algoritmo de Kruskal
começa com uma floresta geradora F
de G.
O processo iterativo é muito simples:
enquanto existe alguma aresta externa,
Cada iteração do algoritmo de Kruskal
começa com uma floresta geradora F
de G.
O processo iterativo é muito simples:
enquanto existe alguma aresta externa,
No início da primeira iteração, cada componente conexa da floresta F tem apenas um vértice. No fim do processo iterativo, F é conexa, uma vez que G é conexo e não há arestas externas a F.
Como se vê, o algoritmo tem caráter guloso: em cada iteração, abocanha a aresta que parece mais promissora localmente sem se preocupar com o efeito global dessa escolha. O algoritmo foi projetado pensando no critério de minimalidade de MSTs baseado em circuitos.
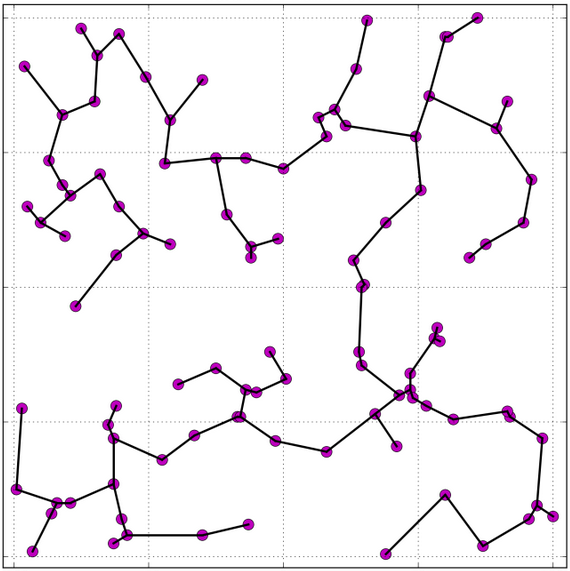
Exemplo A. O vídeo Kruskal's Algorithm Animation no YouTube aplica o algoritmo de Kruskal a um grafo cujos vértices são pontos aleatórios no plano. O grafo é completo e o custo de cada aresta é a distância geométrica entre suas pontas.
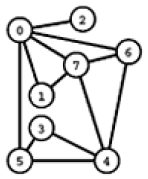
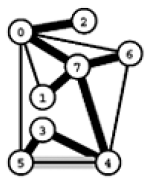
Exemplo B. Considere o problema de encontrar uma MST no grafo não-dirigido com custos nas arestas definido a seguir. (Para simplificar o rastreamento, as arestas são apresentadas em ordem crescente de custo.) Em seguida, veja o rastreamento da execução do algoritmo de Kruskal. Cada linha da tabela registra, no início de cada iteração, as arestas da floresta e o custo da floresta.
3-5 1-7 6-7 0-2 0-7 0-1 3-4 4-5 4-7 0-6 4-6 0-5 0 1 2 3 4 5 6 7 8 9 9 11
floresta custo - 0 3-5 0+0 3-5 1-7 0+1 3-5 1-7 6-7 1+2 3-5 1-7 6-7 0-2 3+3 3-5 1-7 6-7 0-2 0-7 6+4 3-5 1-7 6-7 0-2 0-7 3-4 10+6 3-5 1-7 6-7 0-2 0-7 3-4 4-7 16+8
A última linha dá as arestas de uma MST. Resumindo, o algoritmo de Kruskal escolhe as seguintes arestas para formar uma MST:
3-5 1-7 6-7 0-2 0-7 3-4 4-7 0 1 2 3 4 6 8
(Os espaços em branco correspondem às arestas que foram rejeitadas porque formam um circuito com as arestas escolhidas em iterações anteriores.)
0 1 2 3 4 5 (1,3) (2,1) (6,5) (3,4) (3,7) (5,3)
Aplique o algoritmo de Kruskal a esse grafo. Exiba uma figura do grafo e da floresta no início de cada iteração. Dê a ordem em que o algoritmo descobre as arestas da MST.
UGraph naiveK( UGraph G) {
UGraph F = UGRAPHinit( G->V);
while (true) {
int min = INFINITY;
vertex x, y;
for (vertex v = 0; v < G->V; ++v)
for (link a = G->adj[v]; a != NULL; a = a->next) {
if (GRAPHreach( F, v, a->w)) continue;
if (a->c < min) {
min = a->c;
x = v, y = a->w;
}
}
if (min == INFINITY)
return F;
UGRAPHinsertEdge( F, x, y, min);
}
}
Para obter uma boa implementação do algoritmo de Kruskal, é preciso escolher duas estruturas de dados: uma para representar a floresta geradora (e a MST final) e uma estrutura auxiliar que permita decidir facilmente se uma aresta é externa a uma dada floresta geradora.
Como representar a floresta geradora? A representação por vetor de pais que usamos em outros algoritmos é incômoda no caso do algoritmo de Kruskal. Adotaremos como representação uma simples lista das arestas da floresta, armazenada num vetor. Cada aresta v-w será representada por uma struct edge, construída por uma função EDGE():
typedef struct {
vertex v, w;
int c;
} edge;
static edge EDGE( vertex v, vertex w, int c) {
edge e;
e.v = v, e.w = w; e.c = c;
return e;
}
Para decidir arestas externas, usaremos um vetor de chefes assim construído: (1) eleja um dos vértices de cada componente conexa da floresta para ser o chefe da componente; (2) para cada vértice v do grafo, denote por chefe[v] o chefe da componente que contém v; (3) agora, uma aresta v-w é externa à floresta se e somente se chefe[v] ≠ chefe[w].
Decididas essas estruturas, podemos escrever uma implementação simples do algoritmo de Kruskal. A função UGRAPHmstK0() abaixo recebe um grafo não-dirigido conexo G e armazena no vetor mst[] as arestas de uma MST do grafo. É claro que mst[] terá G->V-1 elementos. A função usa uma constante INFINITY de valor maior que o custo de qualquer aresta do grafo.
#define UGraph Graph
void UGRAPHmstK0( UGraph G, edge mst[])
{
vertex chefe[1000];
for (vertex v = 0; v < G->V; ++v)
chefe[v] = v;
int k = 0;
while (true) {
// a floresta tem arestas mst[0..k-1]
int min = INFINITY;
vertex x, y;
for (vertex v = 0; v < G->V; ++v) {
for (link a = G->adj[v]; a != NULL; a = a->next) {
vertex w = a->w; int c = a->c;
if (v < w && chefe[v] != chefe[w] && c < min) {
min = c;
x = v, y = w;
}
}
}
if (min == INFINITY) return;
mst[k++] = EDGE( x, y, min);
vertex v0 = chefe[x], w0 = chefe[y]; // 1
for (vertex v = 0; v < G->V; ++v) // 2
if (chefe[v] == w0) // 3
chefe[v] = v0; // 4
}
}
As linhas 1 a 4 fazem a união de duas componentes conexas da floresta: a componente que contém x absorve a componente que contém y e as duas passam a ter o mesmo chefe v0.
Essa função é muito lenta. Ela consome V (E + V) unidades de tempo, no pior caso, para processar um grafo não-dirigido com V vértices e E arestas. Como E < V2, podemos dizer que o consumo de tempo é limitado por V3.
Exemplo C. Voltamos a examinar o grafo não-dirigido do exemplo A. Veja a lista de arestas do grafo (em ordem crescente de custos). Cada linha da tabela seguinte registra o estado de coisas no início de uma iteração do while na função UGRAPHmstK0(): a aresta mais recente de mst[], o vetor chefe[], e o custo da floresta.
3-5 1-7 6-7 0-2 0-7 0-1 3-4 5-4 4-7 0-6 4-6 0-5 0 1 2 3 4 5 6 7 8 9 9 11
chefe[] custo da
mst[k-1] 0 1 2 3 4 5 6 7 floresta
0 1 2 3 4 5 6 7 0
3-5 0 1 2 3 4 3 6 7 0+0
1-7 0 1 2 3 4 3 6 1 0+1
6-7 0 6 2 3 4 3 6 6 1+2
0-2 0 6 0 3 4 3 6 6 3+3
0-7 0 0 0 3 4 3 0 0 6+4
3-4 0 0 0 3 3 3 0 0 10+6
4-7 3 3 3 3 3 3 3 3 16+8
Resumindo, o algoritmo de Kruskal escolhe as seguintes arestas para formar uma MST:
3-5 1-7 6-7 0-2 0-7 3-4 4-7 0 1 2 3 4 6 8
for (v = 0; v < G->V; ++v)
if (chefe[v] == chefe[y])
chefe[v] = chefe[x];
A função UGRAPHmstK0() é ineficiente por dois motivos. Primeiro, porque cada iteração examina todas as arestas do grafo à procura da aresta externa mais barata. Segundo, porque cada iteração examina todos os vértices do grafo para atualizar o vetor de chefes. Para corrigir a primeira ineficiência, basta colocar as arestas em ordem crescente de custo e então examinar cada aresta uma só vez. A segunda ineficiência é mais difícil de corrigir: será preciso recorrer à estrutura union-find, que usa um vetor de chefes mais flexível.
A função UGRAPHmstK1() começa por invocar uma função UGRAPHedges() que armazena as E arestas do grafo num vetor e[0..E-1]. Em seguida, invoca uma função sort() para rearranjar e[0..E-1] em ordem crescente de custos. Finalmente, examina as arestas na ordem em que elas estão em e[0..E-1] e escolhe as que farão parte da MST.
#define UGraph Graph
/* A função UGRAPHmstK1() recebe um grafo não-dirigido conexo G com custos arbitrários nas arestas e calcula uma MST de G. O grafo é dado por suas listas de adjacência. A função armazena as arestas da MST no vetor mst[0..V-1], alocado pelo usuário. (A função implementa o algoritmo de Kruskal. O código foi copiado, com ligeiras modificações, do programa 20.5 de Sedgewick.) */
void UGRAPHmstK1( UGraph G, edge mst[]) { edge e[500000]; UGRAPHedges( G, e); int E = G->A/2; sort( e, 0, E-1); UFinit( G->V); int k = 0; for (int i = 0; k < G->V-1; ++i) { vertex v0 = UFfind( e[i].v); vertex w0 = UFfind( e[i].w); if (v0 != w0) { UFunion( v0, w0); mst[k++] = e[i]; } } }
/* Esta função armazena as arestas do grafo não-dirigido G no vetor e[0..E-1]. */
static void UGRAPHedges( UGraph G, edge e[]) { int i = 0; for (vertex v = 0; v < G->V; ++v) for (link a = G->adj[v]; a != NULL; a = a->next) if (v < a->w) e[i++] = EDGE( v, a->w, a->c); }
As funções UFinit(), UFfind() e UFunion() fazem o seguinte:
Para fazer uma implementação eficiente
das funções UFfind() e UFunion(),
vamos usar as ideias do tipo-de-dados abstrato
union-find.
[O union-find
é discutida na seção 1.3
do volume 1 do livro de Sedgewick.
Também aparece no programa 4.8
do livro.
A variante discutida a seguir é menos pura
que a de Sedgewick, mas mais apropriada ao nosso contexto.]
Union-find.
A estrutura union-find é uma flexibilização ch[0..V-1] do
vetor de chefes que já usamos
acima.
A flexibilização consiste no seguinte:
para cada vértice v,
o vértice ch[v]
não mais precisa ser o chefe de v,
desde que seja possível chegar ao chefe iterando ch[],
ou seja,
fazendo
ch[ch[v]],
ch[ch[ch[v]]],
etc.
Com essa flexibilização,
ch[v] passa a ser uma espécie de
superior imediato
de v.
É claro que v é um chefe
se e somente se
ch[v] ≡ v.
Digamos agora que os chefes de v e w
são v0 e w0 respectivamente.
Se esses dois vértice são diferentes,
a função UFunion() une as componente chefiadas
por v0 e w0
em uma só tornando v0 o superior imediato de w0
ou vice versa.
Para evitar que a estrutura fique muito alta
(isto é, que seja necessário iterar ch[] muitas vezes
para chegar a um chefe),
a função UFunion() faz com que o chefe da maior
das duas componente seja também o chefe da menor.
(Esse truque é conhecido como union-by-rank.)
O tamanho
das componentes é mantido em um vetor sz[]:
se v0 é um chefe
então sz[v0] é o número de vértices
chefiados por v0.
/* A função UFfind() devolve o chefe de v (ou seja, o chefe da componente conexa que contém v na floresta geradora mst[0..k-1]). A função UFunion() recebe dois chefes distintos v0 e w0 e faz a união das correspondentes componentes. */
static vertex ch[1000]; static int sz[1000]; void UFinit( int V) { for (vertex v = 0; v < V; ++v) { ch[v] = v; sz[v] = 1; } } vertex UFfind( vertex v) { vertex v0 = v; while (v0 != ch[v0]) v0 = ch[v0]; return v0; } void UFunion( vertex v0, vertex w0) { if (sz[v0] < sz[w0]) { ch[v0] = w0; sz[w0] += sz[v0]; } else { ch[w0] = v0; sz[v0] += sz[w0]; } }
Com essa implementação,
a altura
de cada estrutura de superiores imediatos
(ou seja, o número de repetições de ch[]
necessário para se chegar a um chefe)
não passa de log V,
sendo V o número de vértices de G.
Assim,
cada invocação de UFfind() e UFunion()
consome log V
unidades de tempo no máximo.
(Poderíamos fazer uma implementação mais eficiente
embutindo o truque path compression
no código de UFfind().
Isso faria com que cada operação consumisse apenas
log* V
unidade de tempo no pior caso.
Mas a função UGRAPHmstK1()
não se beneficiaria desse melhoramento
porque a primeira parte do algoritmo,
que coloca as arestas em ordem,
consome tempo E log V.)
Exemplo D. Considere novamente o grafo não-dirigido do exemplo C. Veja abaixo o vetor e[0..E-1] de arestas do grafo, já em ordem crescente de custos. Logo em seguida, veja os vetores mst[], ch[] e sz[] no início das sucessivas iterações da função UGRAPHmstK1():
3-5 1-7 6-7 0-2 0-7 0-1 3-4 5-4 4-7 0-6 4-6 0-5 0 1 2 3 4 5 6 7 8 9 9 11
mst[] ch[] sz[]
0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7 1 1 1 1 1 1 1 1
3-5 0 1 2 3 4 3 6 7 1 1 1 2 1 1 1 1
3-5 1-7 0 1 2 3 4 3 6 1 1 2 1 2 1 1 1 1
3-5 1-7 6-7 0 1 2 3 4 3 1 1 1 3 1 2 1 1 1 1
3-5 1-7 6-7 0-2 0 1 0 3 4 3 1 1 2 3 1 2 1 1 1 1
3-5 1-7 6-7 0-2 0-7 1 1 0 3 4 3 1 1 2 5 1 2 1 1 1 1
3-5 1-7 6-7 0-2 0-7 3-4 1 1 0 3 3 3 1 1 2 5 1 3 1 1 1 1
3-5 1-7 6-7 0-2 0-7 3-4 4-7 1 1 0 1 3 3 1 1 2 8 1 3 1 1 1 1
Veja a evolução da estrutura union-find à medida que arestas são acrescentadas à MST:
1
3 7 6 0
2
5 4
3-5
1
3 7 6 0
_|
| 2
5 4
1-7
1
|
|
3 7 6 0
_|
| 2
5 4
6-7
1
|__
| |
3 7 6 0
_|
| 2
5 4
0-2
1
|__
| |
3 7 6 0
_| |
| 2
5 4
0-7
1
|_____
| | |
3 7 6 0
_| |
| 2
5 4
0-1
3-4
1
|_____
| | |
3 7 6 0
_|_ |
| | 2
5 4
4-5
4-7
1
__|_____
| | | |
3 7 6 0
_|_ |
| | 2
5 4
0-6
4-6
0-5
Desempenho. Digamos que o grafo tem V vértices e E arestas. Então a função sort() consome tempo limitado por E log E. O restante do código de UGRAPHmstK1() consiste em 2V invocações de UFfind() e V invocações de UFunion(), e portanto consome tempo limitado por V log V. Como log E < 2 log V, podemos dizer que o consumo de UGRAPHmstK1() é limitado por
(E + V) log V
no pior caso. Como o grafo é conexo, temos E ≥ V−1 e portanto podemos dizer que o algoritmo consome tempo proporcional a E log V no pior caso. Diz-se que o algoritmo é linearítmico.
3-4 2-4 5-6 0-2 0-3 2-3 4-5 4-6 1-2 3-5 1-6 1-4 2 3 4 5 8 10 12 14 16 18 26 30
0-1 2-3 0-3 4-5 5-6 5-7 6-8 2-7 1 2 3 4 5 6 7 8
enxuto, sem variáveis supérfluas.
A chain is only as strong as its weakest link.