em
Headers HTTP para rastro distribuído (observabilidade) - Parte 1: Spring Cloud Sleuth
Esta série de posts investiga os headers HTTP usados para apoiar o rastro distribuído (tracing), que é um dos pilares da observabilidade (composta também por logs e métricas). Embora foquemos na investigação sobre esses headers, estes posts servem também como uma introdução sobre rastro distribuído e como apresentação de algumas alternativas tecnológicas para sua implementação. Como valor agregado extra, destrinchamos e interpretamos a documentação de algumas dessas alternativas; documentação essa, francamente, não tão fácil de assimilar.
Contexto - rastro distribuído (tracing)
Considere um contexto de microsserviços, em que um serviço A invoca um serviço B (Figura 1). Imagine agora que durante o processamento que ocorre no serviço B, um erro interno aconteça. Devido a esse erro interno, o serviço B devolve uma mensagem de erro interno ao serviço A, mas também produz um registro de log, detalhando o erro acontecido e reportando o instante de sua ocorrência. Diante desse erro interno no serviço B, o serviço A até pode tentar alguma estratégia de degradação suave para seguir adiante, mas possivelmente também produzirá um erro interno. Esse erro interno no serviço A também produzirá um log de erro.
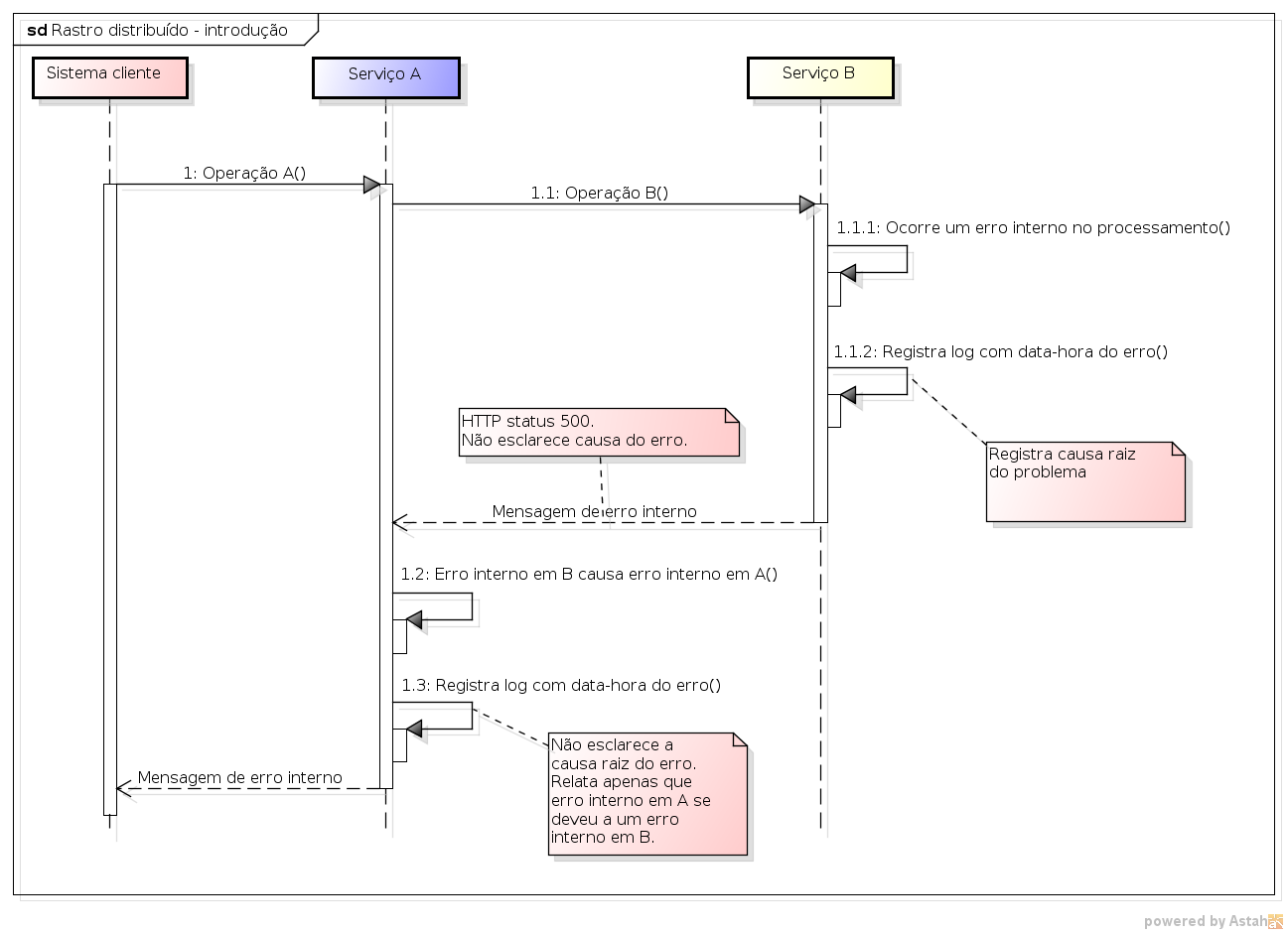
Agora, imagine usuários reclamando para a equipe de desenvolvimento sobre o erro ocorrido no serviço A. Para entender o problema, a equipe investigará o log do serviço A e descobrirá que o erro em A foi devido a um problema no serviço B. E agora vem a questão: como identificar o log de erro do serviço B relacionado ao erro em mão do serviço A? Pois bem, o rastro distribuído (tracing) diz respeito justamente aos processos, padrões e ferramentas que possibilitam que a equipe de desenvolvimento compreenda as requisições feitas a partir da invocação a um determinado serviço, dando a possibilidade de correlacionar erros ocorridos em diferentes serviços, i.e., entender que o erro interno no serviço A foi devido a um determinado problema no serviço B.
Uma solução caseira para rastro distribuído
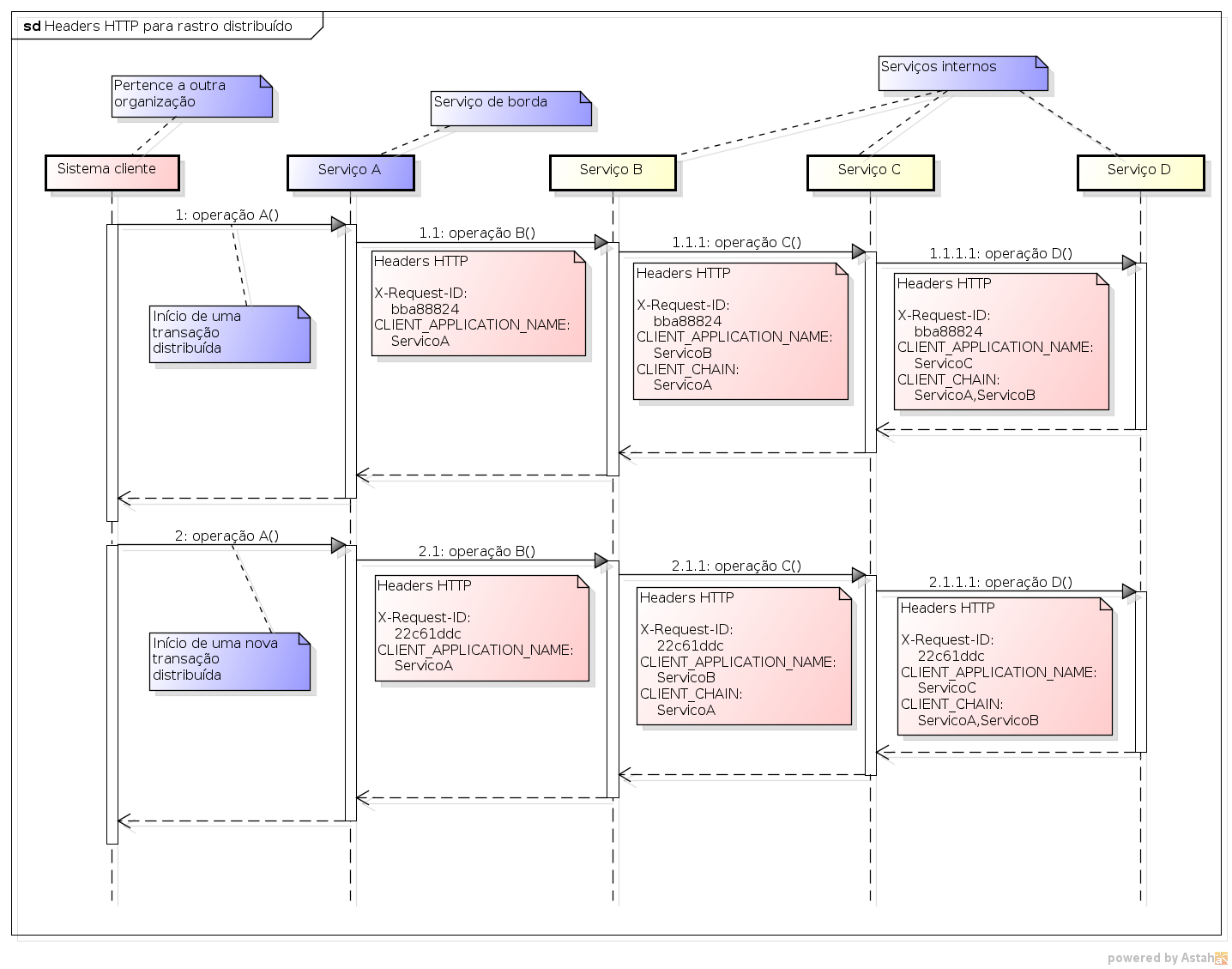
Em minha equipe, implementamos o rastro distribuído com a seguinte estratégia: o serviço de borda (invocado pelo cliente, em nossa caso normalmente uma API REST) gera um UUID que será o “id de rastreabilidade de log”. Qualquer exceção (stack trace) logada estará claramente vinculada a esse id de rastreabilidade. Quando o serviço de borda invoca outro serviço interno nosso, esse id é transferido ao outro serviço por meio do header HTTP X-Request-ID. Assim, caso o serviço interno precise registrar alguma exceção no log, o mesmo id de rastreabilidade será utilizado. E, claro, se esse serviço interno chamar outros serviços internos, o id de rastreabilidade será propagado por meio do mesmo header. Assim, conseguimos vincular logs de diferentes serviços, sabendo que ambos ocorreram no contexto da mesma transação distribuída (i.e., devido à uma invocação específica feita ao serviço de borda).
Temos também outros dois headers que trafegam entre nossos serviços que descrevem a sequência de invocações em uma transação distribuída para o apoio à obtenção de auditorias e métricas:
CLIENT_APPLICATION_NAME: nome do serviço cliente que realizou a invocação. Exemplo: quando o serviço A chama o serviço B, temos queCLIENT_APPLICATION_NAME=A.CLIENT_CHAIN: lista dos nomes dos serviços que fizeram parte da cadeia de invocações até o momento, mas sem conter o serviço chamador e o serviço chamado na requisição que transporta o header (assim, os serviços de borda não precisam passar esse header). Exemplo: sendo A um serviço de borda e B, C e D serviços internos, quando o serviço A chama o serviço B, B chama C e C chama D, na chamada do C ao D temos queCLIENT_CHAIN=A,B.
A figura abaixo resume nosso esquema de headers para o rastro distribuído entre nossos serviços.
O problema - que headers HTTP usar para apoiar o rastro distribuído?
Contudo, criamos esse esquema sem referências, a partir de nossa própria intuição. Passados alguns anos, hora de revisitar nossa solução. Se fôssemos fazer hoje, faríamos algo diferente? Parti então para o estudo de ferramentas e padrões de rastro distribuído, mas tendo como fio condutor do estudo a análise dos headers trafegados nessas soluções de mercado.
Em particular, a questão é: poderíamos ter uma solução caseira utilizando headers de apoio a rastro distribuído que fossem compatíveis com soluções de mercado? Em tese, essa abordagem poderia trazer ganhos de portabilidade e interoperabilidade.
Nessa busca, parti de dois pontos sobre os quais já ouvira falar: o Sleuth (subsistema de rastro distribuído do Spring Boot) e o OpenTracing. Neste primeiro post, focaremos no Sleuth.
Os trechos em azul neste post são citações, em geral das documentações oficiais. Note que esses recortes agregam valor, pois por vezes a essência do que é determinada ferramenta não fica clara pela sua apresentação inicial, principalmente no sentido de entender o quanto ela é complementar ou competidora em relação a outras alternativas. Bom, vamos lá!
Spring Cloud Sleuth
Da documentação oficial do Spring Cloud Sleuth [1], temos que:
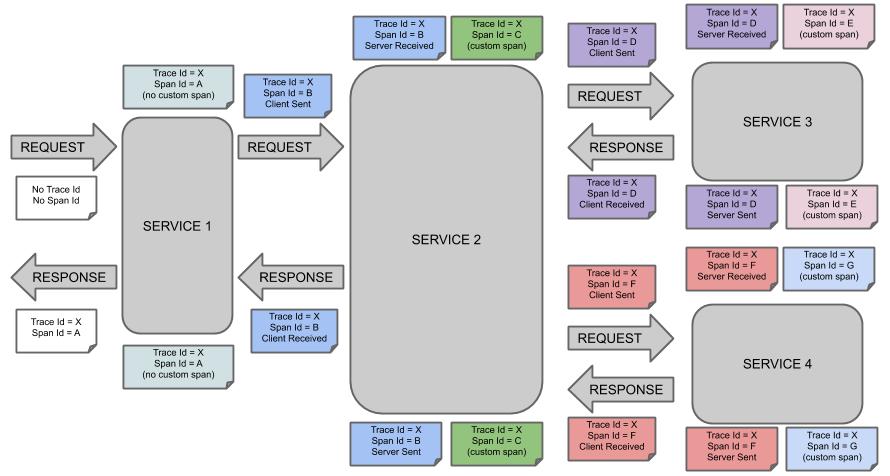
Tracing is simple, in theory. As a request flows from one component to another in a system, through ingress and egress points, tracers add logic where possible to perpetuate a unique trace ID that’s generated when the first request is made. As a request arrives at a component along its journey, a new span ID is assigned for that component and added to the trace. A trace represents the whole journey of a request, and a span is each individual hop along the way. Spans may contain tags, or metadata, that can be used to later contextualize the request. Spans typically contain common tags like start timestamps and stop timestamp, though it’s easy to associate semantically relevant tags like a business entity ID with a span.
Spring Cloud Sleuth automatically instruments common communication channels:
- requests over messaging technologies like Apache Kafka or RabbitMQ;
- HTTP headers received at Spring MVC controllers
- requests made with the RestTemplate, etc.
Spring Cloud Sleuth sets up useful log formatting for you that prints the trace ID and the span ID.
Exemplo de log gerado por uma aplicação utilizando o Sleuth:
2016-02-11 17:12:45.404 INFO [my-service-id,73b62c0f90d11e07,83b62c0f90d11e06,false] 85184 --- [nio-8080-exec-1] com.example.MySimpleComponentMakingARequest
No exemplo acima, 73b62c0f90d11e07 é o trace ID e 83b62c0f90d11e06 é o span ID.
Ou seja, o Sleuth é responsável por gerenciar os trace IDs e os span IDs. Trace ID é um ótimo termo genérico para o nosso header X-Request-ID e pode ser bem traduzido como “ID de rastro”. Já span ID é um termo mais difícil de se traduzir, mas representa o processamento ocorrido em um dos serviços para aquela transação distribuída.
A gerência dos trace e span IDs inclue a gravação dos mesmos nos registros de log, além da transferência desses IDs quando uma chamada é feita de um serviço para outro.
Outra coisa interessante aqui é que existe um contexto de requisição, isto é, um conjunto de tags que pode ser passado de um serviço para o outro.
A seguinte figura da documentação do Sleuth esclarece bem os conceitos de trace e span IDs.
Até aí OK. Mas o que fazer com essas informações? Como visualizá-las? E é aí que entra o OpenZipkin.
OpenZipkin
Na documentação do próprio Sleuth [1] temos a apresentação do OpenZipkin, com a seguinte explicação:
Bring up the UI and then find all the recent traces. You can sort by most recent, longest, etc., for finer-grained control over which results you see.
Ou seja, o OpenZipkin possibilita a visualização dos rastros gerenciados pelo Sleuth. Pelas figuras abaixo, nota-se que é possível visualizar no OpenZipkin o tempo gasto em cada transação distribuída e o tempo gasto em cada serviço no caminho dessa transação. Essa visualização é benéfica pois auxilia na identificação de qual serviço contém o gargalo de desempenho da transação.
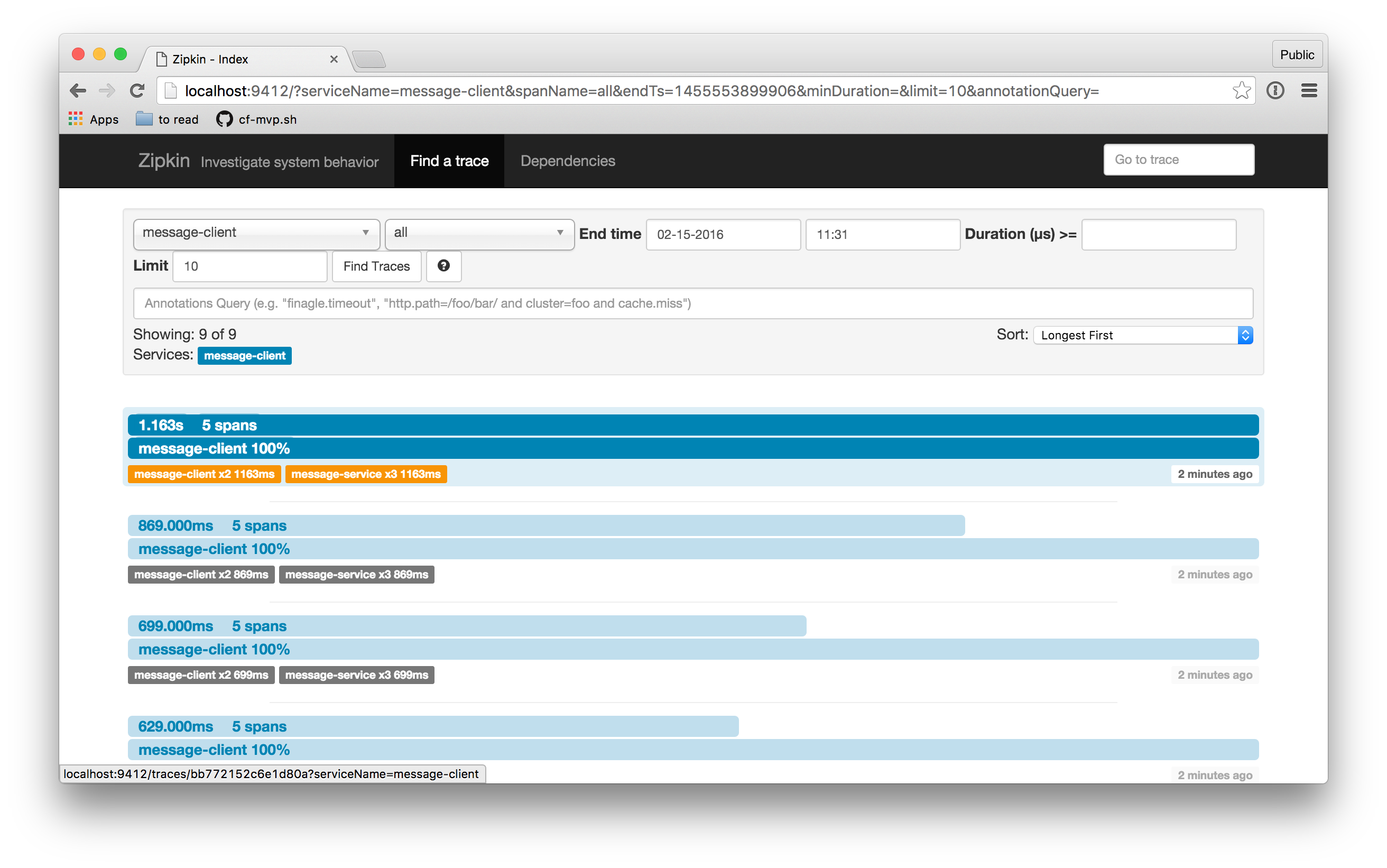
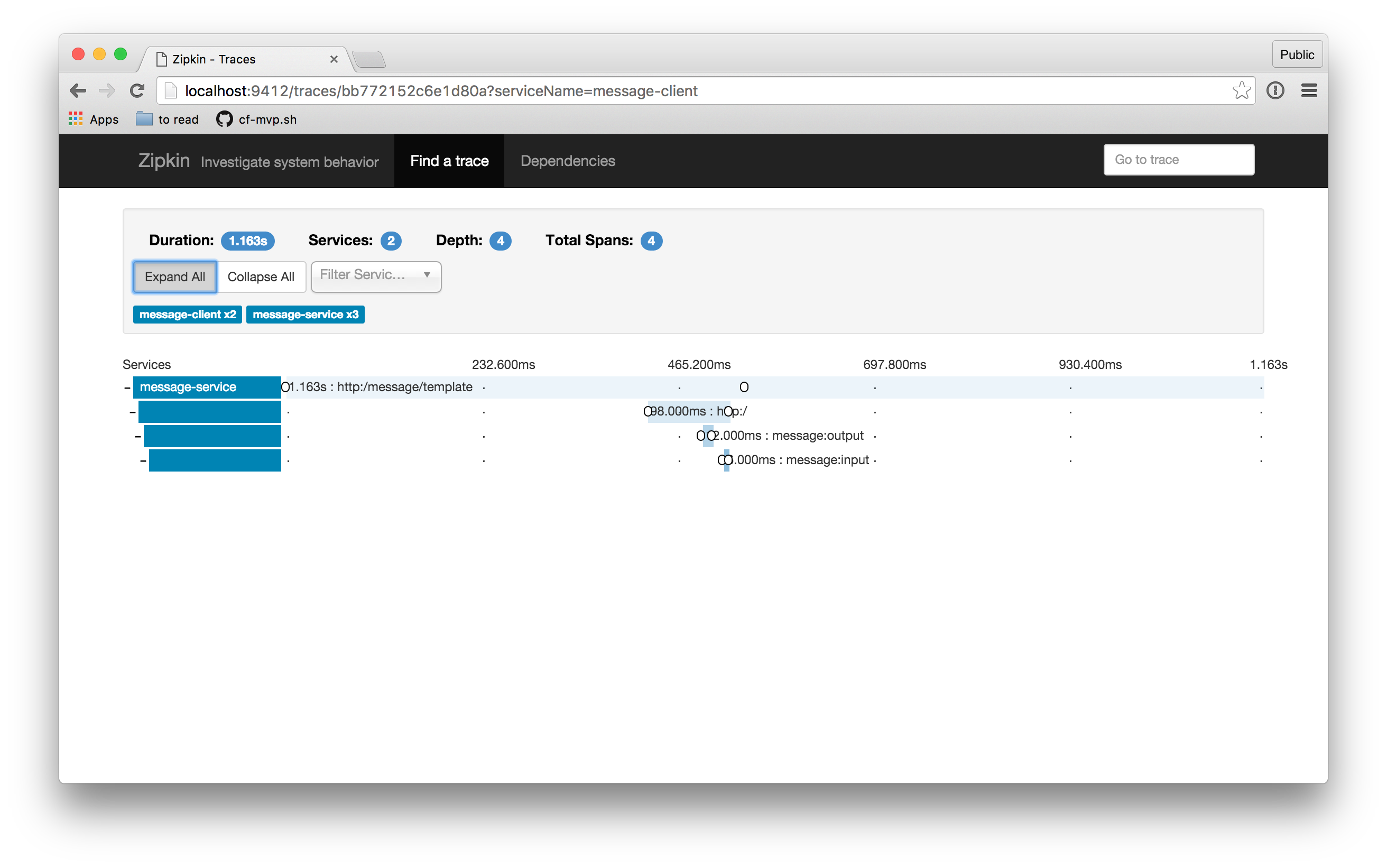
Ao se clicar em um span no OpenZipkin, você ainda consegue visualizar as tags associadas a esse span.
Mas e os headers? Como, concretamente, o trace ID é passado de um serviço ao outro?
Headers no Sleuth
O Sleuth chama a transferência do trace ID entre serviços de “propagação de contexto”.
Na documentação [2] temos que:
Traces connect from service to service using header propagation. The default format is B3.
For Brave we support AWS, B3, W3C propagation types.
Legal, parece que temos aí possíveis padrões de headers. Mas eis que no caminho surge um Brave. O que seria isso? Pois é… por essas e outras que seguir essas documentações é cansativo… Então, parênteses para o Brave!
Parênteses: Brave
No Github do Brave [3], temos que:
Brave is a distributed tracing instrumentation library. Brave typically intercepts production requests to gather timing data, correlate and propagate trace contexts. Typically trace data is sent to Zipkin server.
Ou seja, o Brave (também chamado na documentação do Sleuth de “OpenZipkin Brave tracer”) parece ser a biblioteca cliente do OpenZipkin. Mas não seria isso o próprio Sleuth? Bom, pela documentação do Sleuth:
You can choose to use either Sleuth’s API or the Brave API directly in your code
Confuso, né… não entendi direito e vou então ignorar o Brave como sendo um detalhe de implementação do Sleuth 🙂.
Voltando aos headers no Sleuth
Voltando à documentação do Sleuth sobre propagação de contexto:
Traces connect from service to service using header propagation. The default format is B3. Similar to data formats, you can configure alternate header formats also, provided trace and span IDs are compatible with B3. Most notably, this means the trace ID and span IDs are lower-case hex, not UUIDs. Besides trace identifiers, other properties (Baggage) can also be passed along with the request. Remote Baggage must be predefined, but is flexible otherwise.
Antes de seguir com os formatos de headers, tem outra coisa irritante aqui. Tínhamos visto na documentação inicial do Sleuth sobre a existência de tags. Agora, a documentação fala de “baggage” (bagagem), que parece ser algo parecido. Bom… na mesma página há uma explicação sobre a diferença de tags e baggage. Primeiro, a definição de bagagge:
Distributed tracing works by propagating fields inside and across services that connect the trace together: traceId and spanId notably. The context that holds these fields can optionally push other fields that need to be consistent regardless of many services are touched. The simple name for these extra fields is “Baggage”.
Até aqui, baggage seria o contexto da requisição que é passado de um serviço para o outro. Agora a diferença entre baggage e tags:
Like trace IDs, Baggage is attached to messages or requests, usually as headers. Tags are key value pairs sent in a Span to Zipkin. Baggage values are not added spans by default, which means you can’t search based on Baggage unless you opt-in. To make baggage also tags, use the property spring.sleuth.baggage.tag-fields.
Confuso, não? Bom, a diferença é sutil: baggage é o contexto que um serviço passa para o serviço invocado. Já as tags formam o contexto observável pelo OpenZipkin relativo a um span.
Agora sim, finalmente aos headers! Nesse momento desejamos entender como trace ID, span ID e o resto do contexto da requisição (baggage) são propagados pelo Sleuth nos headers de uma requisição HTTP. Assim poderíamos utilizar esses headers em nossos serviços, mesmo sem necessariamente adotar o Sleuth.
Propagação b3
Na documentação do projeto b3-propagation [4], temos que:
B3 Propagation is a specification for the header “b3” and those that start with “x-b3-“. These headers are used for trace context propagation across service boundaries.
- TraceId: The X-B3-TraceId header is encoded as 32 or 16 lower-hex characters. For example, a 128-bit TraceId header might look like: X-B3-TraceId: 463ac35c9f6413ad48485a3953bb6124.
- SpanId: The X-B3-SpanId header is encoded as 16 lower-hex characters. For example, a SpanId header might look like: X-B3-SpanId: a2fb4a1d1a96d312.
- ParentSpanId: The X-B3-ParentSpanId header may be present on a child span and must be absent on the root span. It is encoded as 16 lower-hex characters. For example, a ParentSpanId header might look like: X-B3-ParentSpanId: 0020000000000001
Ou seja, em resumo, o header que transporta o trace ID é o X-B3-TraceId, enquanto que o header que transporta o SpanID é o X-B3-SpanId.
Propagação padronziada pela W3C
Sim, temos uma proposta da W3C para headers de rastros distribuídos [5]! Vejamos:
This specification defines standard HTTP headers and a value format to propagate context information that enables distributed tracing scenarios. The specification standardizes how context information is sent and modified between services. Context information uniquely identifies individual requests in a distributed system and also defines a means to add and propagate provider-specific context information.
This section describes the binding of the distributed trace context to traceparent and tracestate HTTP headers.
The traceparent header represents the incoming request in a tracing system
The tracestate header includes the parent in a potentially vendor-specific format
The traceparent HTTP header field identifies the incoming request in a tracing system. It has four fields:
- version
- trace-id
- parent-id
- trace-flags
trace-id: This is the ID of the whole trace forest and is used to uniquely identify a distributed trace through a system.
parent-id: This is the ID of this request as known by the caller (in some tracing systems, this is known as the span-id).
Ou seja, na recomendação da W3C, o trace ID não é enviado em um header dedicado, mas sim como um campo (trace-id) no header traceparent, que contém também outras informações (inclusive o campo parent-id, que representa o span ID).
Headers para a bagagem
Segundo a documentação do Sleuth [6]:
Baggage is a set of key:value pairs stored in the span context. Baggage travels together with the trace and is attached to every span. Spring Cloud Sleuth understands that a header is baggage-related if the HTTP header is prefixed with baggage-.
Na sequência, a documentação exibe um trecho de código configurando a bagem a ser propagada:
ExtraFieldPropagation.set("foo", "bar");
Não fica totalmente esclarecido, mas fica subentendido que nesse caso o par chave-valor ("foo", "bar") seria propagado no header baggage-foo com o valor bar.
Visualizando os headers e usando o Zipkin
Para conferir como o Sleuth funciona na prática, o colega Amrut Prabhu escreveu um post bem legal [7]. Ele intercepta uma requisição, no contexto da utilização do Sleuth, e mostra que encontrou os seguintes headers:
x-b3-traceid:"222f3b00a283c75c"
x-b3-spanid:"13194db963293a22"
x-b3-parentspanid:"222f3b00a283c75c"
Ou seja, conforme esperado, o serviço chamador propagou o contexto por meio dos headers b3, que são o default do Sleuth.
Além disso, para entender o OpenZipkin é instrutivo ver como Prabhu configura a integração entre a aplicação e o OpenZipkin.
Visualizing Traces with Zipkin. To integrate Zipkin with the application, we would need to add a Zipkin client dependency to the application.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
On adding this dependency, the Zipkin client by default sends the traces to the Zipkin server at port 9411.
Configuration:
spring:
zipkin:
baseUrl: http://localhost:9411
Essa configuração ajuda a esclarecer a arquitetura: a aplicação, por meio do Spring Sleuth, “empurra” a informação sobre o rastro para o OpenZipkin.
Conclusão
O Sleuth é parte do Spring Boot, framework muito popular para o desenvolvimento de aplicações web em Java. Um serviço utilizando o Sleuth terá cada entrada em seu log associada a um span ID e a um trace ID, sendo que o span ID identifica o processamento ocorrido no serviço, enquanto que o trace ID representa a transação distribuída.
O span ID tipicamente é transferido de um serviço ao outro pelo header X-B3-SpanId, enquanto que o trace ID é transferido pelo header X-B3-TraceId. Outros dados vinculados à transação distribuída podem ser transferidos entre os serviços por meio da “bagagem”, que são headers extras com nomes iniciados em baggage-.
O Sleuth também pode expor todos esses valores mencionados ao OpenZipkin, que é uma interface visual que possibilita a análise por humanos sobre detalhes das transações distribuídas, principalmente o tempo de processamento gasto em cada serviço.
Um grande problema para adotar o Sleuth é encarar sua documentação. Alguns dos problemas enfrentados: versões similares mas diferentes da documentação são encontradas, dificuldade em se encontrar a documentação das classes e métodos do Sleuth, exposição de conceitos desconhecidos que interrompem o fluxo de leitura e falta de foco no leitor (exposição de detalhes aparentemente internos). Além disso tudo, sobre o problema investigado (headers HTTP para rastro distribuído), a documentação é bem omissa. É preciso cavar fundo para encontrar algo.
No próximo post da série seguiremos a investigação analisando o OpenTracing. Pelo o que ouvira falar, me parecia ser um padrão (standard) para a implementação de observabilidade, o que seria muito promissor para nossos objetivos (aplicação, mesmo que parcial, de um padrão bem estabelecido para rastro distribuído em uma solução caseira). Mas ocorre que, surpreendentemente, o próprio OpenTracing se declara não ser um padrão. Veremos sobre o OpenTracing no próximo post…
Referências
[1] Documentação sobre o Sleuth: https://spring.io/blog/2016/02/15/distributed-tracing-with-spring-cloud-sleuth-and-spring-cloud-zipkin
[2] Documentação do Sleuth contendo informações sobre propagação de contexto: https://docs.spring.io/spring-cloud-sleuth/docs/current-SNAPSHOT/reference/html/project-features.html#features-context-propagation
[3] Github do Brave: https://github.com/openzipkin/brave
[4] Documentação do projeto b3-propagation: https://github.com/openzipkin/b3-propagation
[5] Proposta da W3C para headers de rastros distribuídos: https://www.w3.org/TR/trace-context/#trace-context-http-headers-format
[6] Outra documentação sobre a propagação de contexto do Sleuth: https://cloud.spring.io/spring-cloud-sleuth/2.0.x/multi/multi__introduction.html#_propagating_span_context
[7] Post de Amrut Prabhu mostrando os headers b3 e configurando a integração com o OpenZipkin: https://refactorfirst.com/distributed-tracing-with-spring-cloud-sleuth