We begin this section with the presentation of the folklore algorithm which is the starting point for most of the known algorithms to find an lcs of two given sequences.
Let ![]() and
and ![]() be
sequences of lengths n and m over an alphabet A.
We assume that each
be
sequences of lengths n and m over an alphabet A.
We assume that each ![]() and
and ![]() is a letter in A.
The folklore algorithm consists of computing the length
d(i,j) of an lcs of
is a letter in A.
The folklore algorithm consists of computing the length
d(i,j) of an lcs of ![]() and
and
![]() .
This can be done by observing that d(0,0)=0 and by
repeatedly applying the formula:
.
This can be done by observing that d(0,0)=0 and by
repeatedly applying the formula:
![]()
Having computed the matrix d the length of an lcs
of u and v is
d(n,m) and a common subsequence of length d(n,m) can be
computed easily proceeding backwards: from d(n,m) to
d(0,0).
Figure 1 shows an application of
the folklore algorithm.
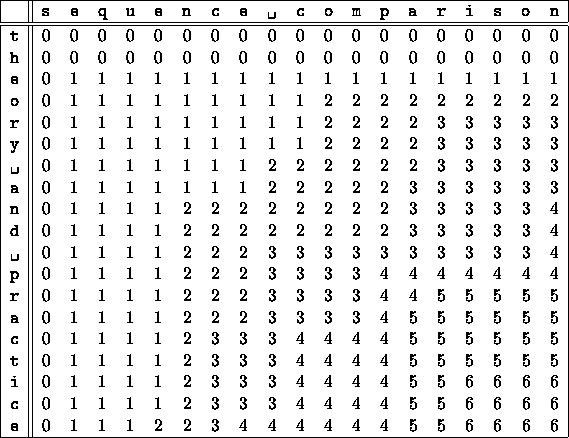
Figure 1:
An example for the folklore algorithm
The time complexity of this algorithm is clearly O(nm); actually this time does not depend on the sequences u and v themselves but only on their lengths. By choosing carefully the order of computing the d(i,j)'s one can execute the above algorithm in space O(n+m). Even an lcs can be obtained within this time and space complexities but this requires a clever subdivision of the problem [19].
An important property of this dynamic programming algorithm is that it can easily be generalized to computing the minimum cost of editing u into v given (possibly different) costs of the operations: changing a letter into another and deleting or inserting a letter [46].
The literature contains a large number of variants of this
algorithm, most of them are recorded in the bibliography.
Just to give some idea about the various time bounds
Table 1 lists
a few results, where we assume that u and
v have the same length n.
In the table p denotes the length of the result (an lcs of
u and v).
Also, r denotes the number of matches, i.e. the
number of pairs ![]() for which
for which
![]() .
.
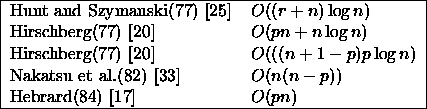
Table 1:
Time complexities of some lcs algorithms
None of the algorithms in Table 1 have worst
case time complexity better than ![]() , some are even
worse.
This can be seen by observing that the value of p varies
between 0 and n, while that of r varies between 0
and
, some are even
worse.
This can be seen by observing that the value of p varies
between 0 and n, while that of r varies between 0
and ![]() and their average value, for pairs of sequences
over a fixed alphabet, is proportional,
respectively, to n and
and their average value, for pairs of sequences
over a fixed alphabet, is proportional,
respectively, to n and ![]() .
It is important to note, however, that, for particular
cases, some of the algorithms might use considerably less
time than in the worst case.
A lively description, from a unified viewpoint, of two of
the main algorithms and some variations can be found in
[7], a recent paper by Apostolico and Guerra.
.
It is important to note, however, that, for particular
cases, some of the algorithms might use considerably less
time than in the worst case.
A lively description, from a unified viewpoint, of two of
the main algorithms and some variations can be found in
[7], a recent paper by Apostolico and Guerra.
The most interesting theoretical result is that of Masek and
Paterson [29].
Carefully using subdivision techniques similar to the ones
used in the ``Four russian's algorithm'' they transformed the
folklore algorithm into one with time complexity
![]() .
This is indeed the only evidence that there exist faster
algorithms than the folklore one.
.
This is indeed the only evidence that there exist faster
algorithms than the folklore one.
Before talking about lower bounds we would like to clarify
the model we think is appropriate for the lcs problem.
First, the time complexity should be measured on a random
access machine under the unit cost model.
This seems to be the correct model because we are
interested in practical algorithms and this is the
closest we can get to existing computers.
Second, the time complexity should be measured in terms of
the total size, say t, of the input, instead of simply
considering the length, say n, of the input sequences.
This is a delicate point.
For sequences over a known and fixed alphabet we can consider
t=n and this was the case considered until now.
The other common assumption is to consider sequences over a
potentially unbounded alphabet.
In this case we assume that the letters are coded over some
known, fixed and finite auxiliary alphabet; hence, to
represent n different symbols we need size
![]() .
Thus, measuring complexity in terms of n or t turn out
to be very different!
.
Thus, measuring complexity in terms of n or t turn out
to be very different!
This model adjusts very well to the current philosophy of text files whenever each line is considered as a letter. In particular, this is the case of the file comparison utilities, our main example for the unbounded alphabet model. In essence we propose that in this case complexity should be measured in terms of the length of the files instead of their number of lines. The main consequence of this proposal is that it increases considerably, but within reasonable bounds, the world of linear algorithms: just for one example, sorting the lines of a text file can be done in linear time [2, 30].
The existing lower bounds for the complexity of the longest common subsequence problem [14, 1, 47, 21] are based on restricted models of computations and do not apply to the model we just proposed. This point seems to be responsible for a certain amount of confusion because sometimes the known lower bounds tend to be interpreted outside the model for which they were obtained. Indeed, as far as we are aware of, no known lower bound excludes the existence of a linear algorithm in the sense just outlined.
Another very interesting, apparently difficult and little
developed area is the probabilistic analysis of the
quantities envolved in the lcs problem.
Let f(n,k) be the average length of the lcs
of two sequences of length n over an alphabet A of k
letters (the uniform distribution on ![]() is assumed).
The function f(n,k) has been explicitly computed for
small values of n and k in [11].
On the asymptotic side it is known that for every k there
exists a constant
is assumed).
The function f(n,k) has been explicitly computed for
small values of n and k in [11].
On the asymptotic side it is known that for every k there
exists a constant ![]() such that
such that
![]()
Thus, fixing the finite alphabet A, the length of an lcs
of two random sequences in ![]() is ultimately proportional to
n.
is ultimately proportional to
n.
The exact determination of ![]() seems elusive and only
lower and upper bounds are known for small values of k.
Some results in this direction appear in
Table 2. For more details, see
[37, 13, 10].
seems elusive and only
lower and upper bounds are known for small values of k.
Some results in this direction appear in
Table 2. For more details, see
[37, 13, 10].
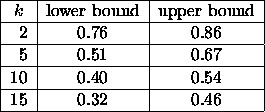
Table 2:
Some upper and lower bounds for ![]()
An interesting conjecture was made by Sankoff and
Mainville [37]:
![]()
We close this section mentioning five results related, in one way or another, to the lcs problem.
A very important subproblem is obtained by restricting the
input to permutations (sequences in which each
letter occurs at most once).
This case was solved by Szymansky [42] in time
![]() .
Such an algorithm is also contained in work of Hunt and
Szymanski [25] and that of Hunt and McIlroy
[24].
It is an open problem whether or not the case of
permutations can be done in linear time on the model we
proposed.
.
Such an algorithm is also contained in work of Hunt and
Szymanski [25] and that of Hunt and McIlroy
[24].
It is an open problem whether or not the case of
permutations can be done in linear time on the model we
proposed.
A further restriction leads to yet another very important
subproblem.
This is obtained if we consider
![]() as one of the permutations, assuming, of
course, the alphabet [1,n].
Then an lcs is just a longest increasing subsequence of the
second permutation and this
problem is part of a very rich theory of
representations of the symmetric group using Young tableaux
extensively studied by A. Young, G de B. Robinson, C. E.
Schensted and M. P. Schützenberger.
A survey focusing on the computational aspects can be found
in Knuth's book [26] from which Fredman [14]
extracted an algorithm to solve the longest increasing
subsequence problem.
His algorithm runs in time
as one of the permutations, assuming, of
course, the alphabet [1,n].
Then an lcs is just a longest increasing subsequence of the
second permutation and this
problem is part of a very rich theory of
representations of the symmetric group using Young tableaux
extensively studied by A. Young, G de B. Robinson, C. E.
Schensted and M. P. Schützenberger.
A survey focusing on the computational aspects can be found
in Knuth's book [26] from which Fredman [14]
extracted an algorithm to solve the longest increasing
subsequence problem.
His algorithm runs in time ![]() and he also
derives
and he also
derives ![]() as a lower bound for the problem.
But, beware, the lower bound does not apply to our
model!
Using the theory of Young tablaux one can compute the
number of permutations of [1,n] which has a longest
increasing subsequence of any given length.
Extensive calculations can be found in [8].
However, the expected value of the length of a
longest increasing subsequence of a permutation of length
n is not known but the data compiled in [8]
indicate that this value is approximately
as a lower bound for the problem.
But, beware, the lower bound does not apply to our
model!
Using the theory of Young tablaux one can compute the
number of permutations of [1,n] which has a longest
increasing subsequence of any given length.
Extensive calculations can be found in [8].
However, the expected value of the length of a
longest increasing subsequence of a permutation of length
n is not known but the data compiled in [8]
indicate that this value is approximately ![]() .
.
The third related problem is obtained if we look for a longest common segment of two sequences instead of a longest common subsequence. In [12] a linear algorithm was obtained to solve this problem.
The fourth related problem is obtained by considering
mini-max duality:
instead of looking for the longest common subsequence what
about a shortest uncommon subsequence?
In 1984 the author solved this problem with an algorithm of
time complexity O(|A|+|u|+|v|).
More precisely, this (unpublished) linear algorithm computes
a shortest sequence which distinguishes the sequences u
and v over the alphabet A, that is to say,
a shortest sequence
which is a subsequence of exactly one of the unequal
sequences u and v.
For instance, consider
sequence comparison and theory and practice:
eee distinguishes them
while cc does not.
A shortest distinguisher is given by d.
The last related problem is a negative result (from our point of view). It was shown by Maier [28] that deciding whether or not a finite set of sequences has a common subsequence of length k is an NP-complete problem. Other related NP-complete problems can be found in [15].