- binmode FILEHANDLE
- faz com que o arquivo seja lido e/ou escrito no modo binário ao invés do modo texto
- close FILEHANDLE
- fecha o arquivo ou o pipe associado ao FILEHANDLE
- eof [FILEHANDLE]
- retorna 1 se a próxima leitura do arquivo for retornar o fim do arquivo ou se o arquivo não está aberto. Retorna 0, caso contrário. Se FILEHANDLE for omitido, será assumido o último arquivo lido
- fileno FILEHANDLE
- retorna o número do descritor do arquivo
- flock FILEHANDLE, MODO
- Executa a chamada ao sistema flock(2) para o arquivo. O modo pode ser 1 (compartilhado), 2 (exclusivo), 4 (non-blocking) ou 8 (unlock)
- getc [FILEHANDLE]
- retorna o próximo caractere do arquivo ou uma string nula se o fim do arquivo já tiver sido atingido. Se o FILEHANDLE for omitido, será assumido o dispositivo padrão de entrada (STDIN)
- open FILEHANDLE [, ARQ]
- abre o arquivo de nome ARQ associando com o
manipulador FILEHANDLE. Se ARQ for omitido, uma variável escalar com o mesmo
nome do FILEHANDLE deve conter o nome do arquivo. Ao abrir um arquivo é
possível especificar o modo de abertura da seguinte forma:
"<ARQ" - somente leitura. Equivale a "ARQ"
">ARQ" - escrita, criando se necessário
">>ARQ" - escrita no final do arquivo
"+>ARQ" - leitura e escritaÉ possível executar um programa usando a função open. Chamamos isto de criar um pipe pelo qual o programa Perl e o outro programa podem se comunicar. Para executar o programa de nome CMD fazemos:
"CMD|" - o programa CMD será executado, e seu dispositivo padrão de saída funcionará como o arquivo associado ao FILEHANDLE
"|CMD" - o que for escrito no FILEHANDLE será enviado para o dispositivo padrão de entrada do programa CMD. A execução do programa será iniciada quando o pipe for fechado - print [FILEHANDLE] LISTA
- escreve os elementos da LISTA no arquivo. Se
FILEHANDLE for omitido será assumido o dispositivo padrão de saída (STDOUT),
ou o arquivo selecionado pela função select. Uma outra forma de utilizar esta
função é definir uma área de impressão, da seguinte forma:
print <<"ROTULO"; ... ROTULO
- read FILEHANDLE, $VAR, QUANT [, POS]
- lê QUANT bytes do arquivo, a partir da posição POS, ou da posição corrente, se POS for omitido, e coloca na variável $VAR. Retorna o número de bytes lidos
- seek FILEHANDLE, POS, MODO
- posiciona o apontador para o arquivo na posição POS. O parâmetro MODO indica a que posição do arquivo POS é relativo: 0, ao início do arquivo; 1, à posição corrente; 2, ao final do arquivo. Se modo for igual a 1 ou 2, POS pode ser negativo. Retorna 1 se o seek foi bem sucedido, 0 caso contrário
- select [FILEHANDLE]
- seleciona o arquivo como default para as operacoes de escrita. Se FILEHANDLE for omitido, retorna o FILEHANDLE correntemente selecionado
- sprintf EXPRESSÃO, LISTA
- retorna a EXPRESSÃO interpolada com os
elementos da lista. Na EXPRESSÃO podem ser usadas máscaras com a forma
%[m[.n]]x onde m e n são números e x pode ser:
- c
- caractere
- d
- número inteiro
- e
- número em notação científica
- f
- número em ponto flutuante
- g
- número compacto em ponto flutuante
- ld
- número inteiro longo
- lo
- número octal longo
- lu
- número inteiro longo sem sinal
- lx
- número hexadecimal longo
- o
- número octal
- s
- string
- u
- número inteiro sem sinal
- x
- número hexadecimal
- X
- número hexadecimal com letras maiúsculas
- sysread FILEHANDLE, EXPRESSÃO, QUANT [, POS]
- lê QUANT bytes do arquivo, a partir da posição POS, ou da posição corrente, se POS for omitido, e coloca na variável $VAR
- syswrite FILEHANDLE, $VAR, QUANT [, POS]
- escreve QUANT bytes da variável $VAR no arquivo, a partir da posição POS, ou da posição corrente, se POS for omitido
- tell [FILEHANDLE]
- retorna a posição corrente do arquivo. Se FILEHANDLE for omitido será assumido o último arquivo lido
1.13 Funções para manipulação de arquivos e
diretórios
As funções para manipulação de arquivos que operam sobre uma lista de arquivos
retornam o número de arquivos para os quais a função foi executada com
sucesso.
- chdir [EXPRESSÃO]
- muda o diretório corrente. Se EXPRESSÃO for omitida será assumido $ENV{HOME} ou $ENV{LOGNAME}
- chmod LISTA
- modifica as permissões de acesso aos arquivos da LISTA. O primeiro elemento da LISTA precisa ser o código das permissões no modo numérico
- chown LISTA
- modifica o proprietário e o grupo a que pertencem os arquivos da lista. Os dois primeiros elementos da LISTA precisam ser o o número do usuário (uid) e o número do grupo (gid)
- closedir DIRHANDLE
- fecha o diretório associado a DIRHANDLE, aberto com a função opendir
- link NOVO, VELHO
- cria o arquivo NOVO linkado ao arquivo VELHO
- lstat ARQUIVO
- retorna um vetor de 13 elementos com informações sobre o arquivo. As posições do vetor têm o seguinte significado: 0: número do dispositivo, 1: i-node, 2: permissões, 3: número de links para o arquivo, 4: uid, 5: gid, 6: nome do dispositivo, 7: tamanho em bytes, 8: data do último acesso, 9: data da última modificação, 10: data da última modificação do i-node, 11: tamanho do bloco, 12: número de blocos. ARQUIVO pode ser um filehandle ou o nome de um arquivo. Retorna uma lista nula se a função não for executada com sucesso
- opendir DIRHANDLE, DIRETÓRIO
- abre o DIRETÓRIO associando-o ao manipulador DIRHANDLE
- readdir DIRHANDLE
- retorna a próxima entrada (ou uma lista com as próximas entradas, se no contexto de lista) do diretório associado a DIRHANDLE
- readlink EXPRESSÃO
- retorna o nome do arquivo associado ao valor de EXPRESSÃO, que deve ser o nome de um link simbólico
- rename VELHO, NOVO
- altera o nome do arquivo VELHO para NOVO
- rewinddir DIRHANDLE
- posiciona o apontador n primeira entrada do diretório associado a DIRHANDLE
- rmdir DIRETÓRIO
- apaga o DIRETÓRIO se ele estiver vazio
- seekdir DIRHANDLE, n
- posiciona o apontador na n-ésima entrada do diretório associado a DIRHANDLE
- stat ARQUIVO
- semelhante à função lstat, mas se ARQUIVO for um link simbólico serão retornadas as informações relativas ao arquivo associado a ARQUIVO
- symlink VELHO, NOVO
- cria o arquivo NOVO simbolicamente linkado ao arquivo VELHO
- telldir DIRHANDLE
- retorna a entrada corrente do diretório associado a DIRHANDLE
- truncate ARQUIVO, TAM
- trunca o ARQUIVO fazendo com que ele fique com TAM bytes. ARQUIVO pode ser um filehandle ou o nome de um arquivo
- ulink LISTA
- apaga os arquivos da LISTA
- utime LISTA
- modifica a data do último acesso e da última modificação dos arquivos da LISTA. Os dois primeiros elementos da LISTA devem ser as datas de acesso e modificação, respectivamente, no formato numérico
1.14 Funções para interação com o sistema
operacional
- die [LISTA]
- escreve o valor da LISTA no dispositivo padrão de erro (STDERR) e encerra o programa retornando o valor corrente da variável $! (número do erro). Se LISTA for omitida será assumido o valor "Died"
- exec LISTA
- executa o comando do sistema contido na LISTA. Não retorna valor
- exit [EXPRESSÃO]
- finaliza o programa retornando o valor da EXPRESSÃO ou 0 se a EXPRESSÃO for omitida
- getlogin
- nome do usuário
- getpgrp [PID]
- grupo a que pertence o processo de número PID. Se PID for omitido ou se for zero será assumido o processo corrente
- getppid
- número do processo pai do processo corrente
- kill LISTA
- envia um sinal para os processos da LISTA. O primeiro elemento da lista deve ser o nome ou o número do sinal
- setpgrp [PID]
- modifica o grupo a que pertence o processo de número PID. Se PID for omitido ou se for zero será assumido o processo corrente
- sleep [EXPRESSÃO]
- suspende a execução do programa por um número de segundos equivalente ao valor de EXPRESSÃO ou para sempre se a EXPRESSÃO for omitida. Retorna o número de segundos em que o programa de fato esteve suspenso
- syscall LISTA
- executa uma chamada ao sistema. O primeiro elemento da LISTA deve ser o nome da chamada ao sistema e os demais elementos os argumentos da chamada
- system LISTA
- suspende o programa e executa o comando do sistema contido na LISTA. Retorna o código de saída do comando
- warn [LISTA]
- escreve o valor da LISTA no dispositivo padrão de erro (STDERR). Se a LISTA for omitida será assumido o valor "Warning: something's wrong"
Existem ainda operadores para realizar testes em arquivos (como por exemplo, saber se um arquivo é um link simbólico), variáveis e vetores especiais (alguns dos quais já citamos), e variáveis de ambiente. Para obter a documentação completa sobre estes itens, recomendamos a bibliografia citada no início deste capítulo.
1.15 Expressões regulares, busca, substituição e
translação
Uma expressão regular é um conjunto de caracteres que serve para simbolizar um
conjunto de strings. Por exemplo, a expressão regular a* simboliza
todas as strings que iniciam com a letra a. Numa expressão regular,
cada caractere representa ele mesmo, exceto alguns caracteres especiais que
chamamos de meta-caracteres. Alguns deles são:
- .
- um caractere qualquer, exceto quebra de linha
- $
- fim de linha
- [...]
- um dos caracteres representados dentro dos colchetes. Por
exemplo, [ab] simboliza o caractere a ou o caractere b
- [^...]
- qualquer caractere que não seja um dos caracteres representados
por dentro dos colchetes
- +
- denota repetição do caractere anterior uma ou mais vezes
- ?
- um (ou nenhum) caractere
- *
- um conjunto (possivelmente vazio) de caracteres
- {N,M}
- denota repetição do caractere anterior no mínimo N vezes e no
máximo M vezes
- {N}
- denota repetição do caractere anterior N vezes
- {N,}
- denota repetição do caractere anterior no mínimo N vezes
- \w
- alfanumérico, incluindo "_"
- \W
- caractere que não seja alfanumérico
- \s
- espaço em branco
- \S
- caractere que não seja espaço em branco
- \d
- dígito numérico
- \D
- caractere que não seja dígito numérico
- \A
- início de uma string
- \Z
- fim de uma string
- \b
- início ou fim de uma palavra
- \B
- caractere que não seja início ou fim de uma palavra
Para buscar um padrão dentro de uma string usamos o operador m juntamente com o operador =~ (ou !~). Os argumentos para o operador m são uma expressão regular e uma STRING que deve aparecer à esquerda do operador =~ (ou !~). Se a STRING for omitida será assumido o valor da variável $_. Pode-se delimitar a expressão regular com quase qualquer delimitador, mas geralmente usa-se / (barra), caso em que pode-se omitir o m. É possível usar este operador como se fosse uma função, caso em que a expressão regular pode estar ou não dentro de parênteses. Alguns modificadores podem ser usados:
- g
- busca todas as ocorrências. No contexto escalar, este modificador funciona como um iterador
- i
- busca case-insensitive
- m
- trata a STRING como múltiplas linhas
- o
- interpola as variáveis uma única vez
- s
- trata a STRING como uma unica linha
- x
- usa expressões regulares extendidas (que podem conter espaços em branco e comentários)
$anos =~ m/199[0-9]/ , /%[a-fA-F0-9]{2}/sg , $nome !~ m(".s\b")g
Para fazer substituição de padrões dentro de uma string usamos o operador s juntamente com o operador =~ (ou !~). Os argumentos para o operador s são uma expressão regular, uma expressão para substituição e uma STRING que deve aparecer à esquerda do operador =~ (ou !~). Se a STRING for omitida será assumido o valor da variável $_. Pode-se delimitar os argumentos com quase qualquer delimitador, mas geralmente usa-se / (barra). É possível usar este operador como se fosse uma função.
Podem ser usados os mesmos modificadores do operador m e mais o modificador e que faz com que a expressão para substituição seja entendida como código Perl. Todas as substrings da STRING simbolizadas pela expressão regular serão substituídas pelo valor da expressão para substituição e será retornado o número de substituições realizadas ou falso se nenhuma substituição for feita. Eis alguns exemplos de utilização deste operador:
$ano =~ s/1999/2000/ , s/%[a-fA-F0-9]{2}/pack("C",hex($1))/eg , $nome !~ s("caza","casa")g
Para fazer translação de padrões dentro de uma string usamos o operador tr (ou o operador y) juntamente com o operador =~ (ou !~). Os argumentos para o operador tr são uma LISTA DE BUSCA, uma LISTA DE SUBSTITUIÇÃO e uma STRING que deve aparecer à esquerda do operador =~ (ou !~). Se a STRING for omitida será assumido o valor da variável $_. Pode-se delimitar os argumentos com quase qualquer delimitador, mas geralmente usa-se / (barra). É possível usar este operador como se fosse uma função.
Todas os caracteres da STRING contidos na LISTA DE BUSCA serão trocados pelo caractere correspondente na LISTA DE SUBSTITUIÇÃO. Podem ser usados os modificadores c (que indica o complemento da LISTA DE BUSCA), d (que faz com que sejam deletados os caracteres da STRING contidos na LISTA DE BUSCA) e o modificador s (que faz com que as sequências de caracteres da STRING que devem ser traduzidas para o mesmo caractere da LISTA DE BUSCA sejam traduzidas por um único caractere). A função retorna o número de translações realizadas ou falso se nenhuma translação for feita. Eis alguns exemplos de utilização deste operador:
$endereco =~ tr/a/A/ , $nome =~ y("*","x")g
Finalmente, a função study recebe como argumento uma variável e pré-processa esta variável em preparação para realizar operações de busca, substituição e translação.
1.16 Como executar um programa Perl
Para executar um programa Perl é preciso chamar o interpretador Perl e passar
o programa fonte como parâmetro, por exemplo:/usr/bin/perl meuprog.pl
Uma outra forma é colocar na primeira linha do programa fonte o endereço do interpretador Perl precedido de #!, por exemplo:
#!/usr/bin/perl
Neste caso, basta dar permissão de execução para o programa fonte e chamá-lo pela linha de comando. No Unix, para dar permissão de execução para o programa meuprog.pl execute o comando chmod 755 meuprog.pl.
2. O Padrão CGI
Common Gateway Interface (CGI) estabelece um padrão de comunicação
entre servidores HTTP e bancos de dados e outras fontes de informação, padrão
este conhecido como padrão CGI. Um programa é dito CGI se ele segue o
padrão CGI. Estes programas realizam processamento específico de informação e
usualmente produzem código HTML ou texto puro, que será
enviado ao servidor HTTP, e este por sua vez enviará para o cliente WWW que
solicitou o programa CGI.Desta forma é possível fazer com que a WWW tenha um comportamento dinâmico, com páginas criadas dinamicamente em resposta a requisições específicas formuladas pelos usuários da teia. Tal mecanismo permite um número ilimitado de aplicações, das quais citamos apenas algumas:
- Busca de informação em bancos de dados
- Atualização de bancos de dados
- Inscrição em eventos e em entidades
- Assinar livro de visitantes
- Instalar um contador de acessos à página
- Consulta de catálogos
- Compra de produtos, inclusive usando meios eletrônicos de pagamento (cartão de crédito)
- Restringir acesso a certos documentos mediante uso de senhas
- Jogos. A cada jogada uma nova página é gerada contendo a nova configuração do jogo
2.1 Variáveis CGI
Antes de iniciar a execução de um programa CGI, o servidor HTTP inicializa
algumas variáveis de ambiente chamadas de variáveis CGI, que servem
como importante fonte de informação para o programa CGI. Aqui apresentamos uma
tabela contendo as variáveis CGI padrão em um sistema UNIX:
| Variável CGI | Descrição | Exemplo |
|---|---|---|
| AUTH_TYPE | Tipo de autenticação para acesso | Basic |
| CONTENT_LENGTH | Número de bytes usados pelos dados | 9 |
| CONTENT_TYPE | Tipo dos dados | text/plain |
| GATEWAY_INTERFACE | Versão da especificação CGI | CGI/1.1 |
| PATH_INFO | Caminho a ser usado pelo programa CGI | cgi-bin/oracle |
| PATH_TRANSLATED | Caminho absoluto a ser usado pelo programa CGI | /usr/cgi-bin/oracle |
| QUERY_STRING | String contendo os dados | Nome=Paulo+Dias&Idade=23 |
| REMOTE_ADDR | Número IP do cliente | 143.107.95.106 |
| REMOTE_HOST | Nome da máquina do cliente | jaca.ime.usp.br |
| REMOTE_IDENT | Identidade do agente de conexão com o servidor | ppp1.ime.usp.br |
| REMOTE_USER | Nome do usuário do programa cliente | adriano |
| REQUEST_METHOD | Método de requisição usado pelo cliente | POST |
| SCRIPT_NAME | Caminho do aplicativo | cgi-bin/post-query.pl |
| SERVER_NAME | Nome do servidor | www.ime.usp.br |
| SERVER_PORT | Porta onde a requisição foi recebida | 80 |
| SERVER_PROTOCOL | Nome e versão do protocolo de requisição | HTTP/1.0 |
| SERVER_SOFTWARE | Nome e versão do software servidor | APACHE/1.1 |
A variável CONTENT_TYPE especifica o tipo dos dados enviados junto com a requisição HTTP. Os tipos e subtipos registrados são:
| Tipo | Subtipo | Descrição |
|---|---|---|
| Application | octet-stream | Dados binários |
| text | plain, html | Texto |
| multipart | mixed, alternative, digest, parallel | Múltiplos dados de diferentes tipos |
| message | rfc822, partial, external-body | Mensagem encapsulada |
| image | gif, jpeg | Imagem |
| audio | basic | Som |
| video | mpeg | Imagem em movimento |
Se uma variável não for instanciada então ela receberá uma
string vazia (NULL). O servidor criará também uma variável do
tipo HTTP_STRING para conter as informações incluídas no header da
requisição enviado pelo browser (STRING denota o prefixo da linha). Por
exemplo, se for enviada no header a linha:
Accept: text/html, application/binary, audio/basic, image/gif,
video/mpeg
Será criada a ariável HTTP_ACCEPT com o valor text/html,
application/binary, audio/basic, image/gif, video/mpeg
campo1=valor1&campo2=valor2&campo3=valor3 ...
Note que os campos são separados por & (e comercial) e o nome do campo e o
valor associado àquele campo são separados por = (igual). Os espaços em branco
digitados nos campos do formulário são convertidos em + (mais). Os caracteres
acentuados, o c cedilha e os caracteres ` ' ~ ^ " ! ? , ; : # $ % & = +
/ | \ ( ) [ ] { } < > são convertidos para sua representação na tabela ASCII,
em hexadecimal, precedida do símbolo % (veja no Apêndice 2 a tabela ASCII HTML).
Por exemplo, considere o formulário a seguir:
Ao definir o valor João da Silva para o campo nome e
29/02/1972 para o campo nascimento, o browser enviará os
dados do formulário da seguinte forma:
nome=Jo%E3o+da+Silva&nascimento=29%2F02%2F%1972
O programa CGI deve ser capaz de converter esta string para uma lista de
variáveis e valores legíveis. O código Perl a seguir é capaz de fazer esta
conversão:
Outra maneira de passar dados para um programa CGI é usando o método
POST. Neste caso o servidor HTTP colocará os dados do formulário no
dispositivo padrão de entrada (STDIN) do programa CGI. O que define o método
de envio dos dados é o valor atribuído ao atributo method do marcador
form quando da criação do formulário.
O formato mais utilizado pelos programas CGI para enviar sua saída é chamado
de parsed header output. De fato, só é requerido dos servidores HTTP
entender este formato. Este tipo de saída consiste de um cabeçalho e o corpo
da saída, separados por um linha em branco. O cabeçalho deve obrigatoriamente
conter uma linha iniciada com Content-type:. O restante desta linha
deve ser a especificação do tipo e subtipo de mídia contidos no corpo da
saída, conforme a tabela da seção 2.1. Por exemplo: Content-type:
text/html.
Exemplo 1:
Considere o formulário abaixo e o código HTML que o gerou:
Aqui temos o código do programa autenticacao.pl:
Neste exemplo temos um formulário para compra de um computador. A seguir temos
o formulário e o código HTML usado para gerá-lo:
O programa abaixo, pedido.pl, processa o formulário enviando uma confirmação
para o cliente e uma mensagem de correio eletrônico com os dados do pedido
para o encarregado dos pedidos (vendedor@compushop.com.br).
Ao escrever programas CGI é preciso atentar para a segurança impedindo que
pessoas mal-intencionadas usem meta-caracteres para obter resultados
indesejáveis. Suponha, por exemplo, que um determinado programa CGI recebe a
string "%7Crm -rf *", decodifica esta string transformando-a em
"|rm -rf *" e envia esta string como parâmetro para um programa
qualquer. No UNIX isto significa que todos os arquivos do diretório corrente e
seus subdiretórios serão definitivamente apagados. Este é apenas um exemplo do
que pode acontecer se relaxarmos na segurança ao escrever um programa CGI.
Para enviar um cookie, basta que o programa CGI inclua no header da resposta
enviada ao browser uma linha com a seguinte sintaxe:
Set-Cookie: NOME=VALOR [;EXPIRES=DATA] [;DOMAIN=DOMÍNIO] [;PATH=CAMINHO]
[;SECURE]
O parâmetro NOME é o nome do cookie e VALOR é a informação associada a
ele. Esta informação deve ser um conjunto de caracteres que não pode conter
vírgula, ponto-e-vírgula ou espaço em branco. A DATA determina até quando o
cookie deve ser armazenado. Se for omitida, o browser armazenará o cookie na
memória, mas não no disco, de forma que ao fechar o browser o cookie será
apagado. O parâmetro DATA deve ser uma data válida, no seguinte formato:
dia da semana, DD-MMM-AAAA HH:MM:SS GMT
Por exemplo:
Wednesday, 16-Feb-2000 23:12:40 GMT
O valor do parâmetro DOMÍNIO deve ser um domínio (computador ou rede) com no
mínimo 2 ou 3 pontos. Qualquer domínio dentro de COM, EDU, NET, ORG, GOV,
MIL e INT deve ter pelo menos 2 pontos; todos os outros domínios precisam ter
pelo menos 3 pontos. Ao definir um DOMÍNIO, é obrigatório que o programa CGI
esteja sendo executado por um servidor dentro deste DOMÍNIO. Se este parâmetro
for omitido, será assumido o nome (ou número IP) do servidor onde o programa
CGI foi executado.
O parâmetro CAMINHO indica um prefixo do caminho de um diretório. Se omitido,
será assumido o diretório do programa CGI que enviou o cookie (como descrito
no header HTTP). Finalmente, o parâmetro SECURE indica que o cookie só deve
ser enviado pelo browser se for usado o protocolo https. A seguir temos
um exemplo de como enviar um cookie:
Set-Cookie: ID=143; EXPIRES=Friday, 31-Mar-2000 23:12:40 GMT;
DOMAIN=.ime.usp.br; PATH=/cgi-bin;
O nome deste cookie é ID e seu valor é 143. Ele será válido até às 23:12:40
GMT de 31/mar/2000. Quando o browser que recebeu este cookie requisitar
qualquer arquivo dentro de um diretório cujo caminho tenha /cgi-bin como
prefixo, e que esteja em um servidor dentro do domínio ime.usp.br, ele enviará
junto com a requisição o nome e o valor do cookie, da seguinte forma:
Cookie: ID=143
Como falamos anteriormente, os cookies serão recebidos pelo
programa CGI através da variável de ambiente HTTP_COOKIE. O Netscape
Navigator pode armazenar até 300 cookies, no máximo 20 por servidor, com
até 4 kb cada um. Se um cookie exceder 4 kb, seu VALOR será truncado. Ao
exceder o limite de 300 cookies no total ou de 20 cookies por servidor, o
Netscape remove o cookie que tiver sido usado há mais tempo. Se o browser
tiver que enviar vários cookies junto com uma requisição, eles serão enviados
na mesma linha, separados por ponto-e-vírgula:
Cookie: nome1=valor1; nome2=valor2 ...
Se um programa CGI quiser remover um cookie, basta reenviar este cookie com o
mesmo NOME e CAMINHO, mas com uma data de expiração passada. Ao reenviar um
cookie com o mesmo NOME e CAMINHO, o seu valor é alterado.
É importante entender o formato no qual os dados oriundos do preenchimento de
um formulário são enviados para um programa CGI. Usualmente, os clientes WWW
(browsers) enviam os dados digitados em um formulário usando o seguinte
formato, conhecido como application/x-www-form-urlencoded (ou
simplesmente urlencoded):
2.2 Codificação urlencoded<form action=/cgi-bin/teste.pl method=GET>
Nome: <input type=text name=nome>
Data de Nascimento: <input type=text name=nascimento>
<input type=submit>
</form>
#!/usr/bin/perl
# checando qual o método usado para enviar os dados
if ($ENV{REQUEST_METHOD} eq 'POST')
{ # se foi usado o método POST pegar os dados do STDIN
read(STDIN, $buffer, $ENV{CONTENT_LENGTH}); }
else
{ # de outro modo pegar os dados da variável QUERY_STRING
$buffer = $ENV{QUERY_STRING}; }
# separando cada campo e seu valor
@pares = split(/&/, $buffer);
foreach $par (@pares)
{ # jogando o nome do campo na variável campo e seu valor na variável valor
($campo, $valor) = split("=", $par);
# convertendo + em espaço em branco
$valor =~ tr/+/ /g;
# convertendo os caracteres em hexadecimal para sua representaçao ASCII
$valor =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg;
# colocando no hash conteudo os valores dos campos, usando os nomes dos
# campos como chaves
$conteudo{$campo} = $valor;
}
Umas das formas de passar dados para um programa CGI é usando o método
GET. No método GET um URL é seguido do símbolo ? após do qual vem uma
string contendo as informações a serem passadas para o programa
CGI. Como os dados digitados no formulários serão enviados para o programa CGI
como parte do URL, ao usar o método GET não é possivel ocultar os dados
através de criptografia. Sempre que for usado o método GET, o servidor HTTP
colocará uma string contendo os dados do formulário, no formato urlencoded, na
variável de ambiente QUERY_STRING.
2.3 Passando dados para programas CGI
Um programa CGI sempre deve retornar algo para o servidor HTTP que o
chamou. Esta saída deve ser enviada para seu dispositivo padrão de saída
(STDOUT). A saída de um programa CGI pode ser código HTML, texto puro,
uma imagem, um som, um arquivo binário, etc...
2.4 Saída de um programa CGI
Examinaremos dois exemplos de programas CGI escritos em Perl. O primeiro deles
recebe como dados um nome e uma senha, verifica se este nome e senha constam
em um cadastro e em caso afirmativo envia o programa transgif. O
segundo exemplo recebe os dados de um formulário de pedidos, devolve uma
página para o usuário que preencheu o formulário confirmando o recebimento do
pedido e envia uma mensagem de correio eletrônico com os dados legíveis para o
encarregado de processar os pedidos.
2.5 Exemplos de programas CGI
<form action=/cgi-bin/autenticacao.pl method=POST>
Nome: <input name=usuario>
Senha: <input type=password name=senha size=8>
<input type=submit>
</form>
#!/usr/bin/perl
# checando qual o método usado para enviar os dados
if ($ENV{REQUEST_METHOD} eq 'POST')
{ # se foi usado o método POST pegar os dados do STDIN
read(STDIN, $buffer, $ENV{CONTENT_LENGTH}); }
else
{ # de outro modo pegar os dados da variável QUERY_STRING
$buffer = $ENV{QUERY_STRING}; }
# separando cada campo e seu valor
@pares = split(/&/, $buffer);
foreach $par (@pares)
{ # jogando o nome do campo na variável campo e seu valor na variável valor
($campo, $valor) = split("=", $par);
# convertendo + em espaço em branco
$valor =~ tr/+/ /g;
# convertendo os caracteres em hexadecimal para sua representaçao ASCII
$valor =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg;
# colocando no hash conteudo os valores dos campos, usando os nomes dos
# campos como chaves
$conteudo{$campo} = $valor;
}
# criando o pipe onde buscamos no arquivo cadastro o usuário e sua senha
open(BUSCA,"grep -x '$conteudo{usuario},$conteudo{senha}' cadastro |");
if (<BUSCA> ne "")
{ # senha correta, enviando header para transmissão de arquivo binário
print "Content-Type: application/octet-stream\n\n";
# enviando o arquivo /usr/local/bin/transgif
open(ARQ,"/usr/local/bin/transgif");
while (<ARQ>) { print $_; } }
else
{ # senha incorreta, enviando documento HTML com mensagem de erro
print "Content-type: text/html\n\n";
print "<h1>Usuário não cadastrado ou senha incorreta !\n" }
close(BUSCA);
Exemplo 2:
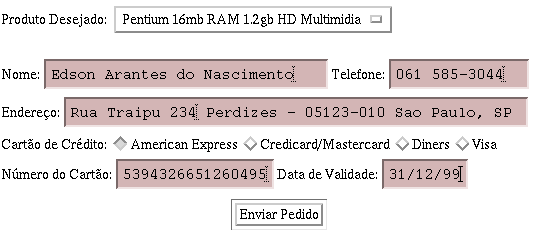
<form action=/cgi-bin/pedido.pl method=GET>
Produto Desejado:
<select name=produto>
<option> Pentium 16mb RAM 1.2gb HD Multimidia
<option> Pentium MMX 200 Mhz 32mb RAM 4.1gb HD Multimidia
<option> Pentium II 400 Mhz 64mb RAM 8.7gb HD Multimidia
<option> Pentium III Xeon 800 Mhz 256mb RAM 12.3gb HD Multimidia
</select><p>
Nome: <input name=comprador size=30>
Telefone: <input name=fone size=14><br>
Endereço: <input name=endereco size=50><brp>
Cartão de Crédito:
<input type=radio name=cartao value=Amex> American Express
<input type=radio name=cartao value=Credicard> Credicard/Mastercard
<input type=radio name=cartao value=Diners> Diners
<input type=radio name=cartao value=Visa> Visa<br>
Número do Cartão: <input name=numero size=16>
Data de Validade: <input name=validade size=8><br>
<center><input type=submit value="Enviar Pedido"></center>
</form>
#!/usr/bin/perl
# checando qual o método usado para enviar os dados
if ($ENV{REQUEST_METHOD} eq 'POST')
{ # se foi usado o método POST pegar os dados do STDIN
read(STDIN, $buffer, $ENV{CONTENT_LENGTH}); }
else
{ # de outro modo pegar os dados da variável QUERY_STRING
$buffer = $ENV{QUERY_STRING}; }
# separando cada campo e seu valor
@pares = split(/&/, $buffer);
foreach $par (@pares)
{ # jogando o nome do campo na variável campo e seu valor na variável valor
($campo, $valor) = split("=", $par);
# convertendo + em espaço em branco
$valor =~ tr/+/ /g;
# convertendo os caracteres em hexadecimal para sua representaçao ASCII
$valor =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg;
# colocando no hash conteudo os valores dos campos, usando os nomes dos
# campos como chaves
$conteudo{$campo} = $valor;
}
# gerando o documento HTML com a confirmação do pedido
print "Content-type: text/html\n\n";
print <<"HTML";
<html>
<head><title>Compushop - Confirmacao de Pedido</title>
<body bgcolor=white>
<h1>Compushop - Confirmação de Pedido</h1>
<hr>Confirmamos o recebimento do seu pedido:<p>
Produto: $conteudo{'produto'}<p>
Nome: $conteudo{'comprador'}<p>
Telefone: $conteudo{'fone'}<p>
Endereço: $conteudo{'endereco'}<p>
Cartão de Crédito: $conteudo{'cartao'}<p>
Número do Cartão: $conteudo{'numero'}<p>
Validade do Cartão: $conteudo{'validade'}<p>
</body>
</html>
HTML
# agora criando a mensagem a ser enviada para vendedor@compushop.com.br
chop($data = `date`);
# criando o pipe para enviar a mensagem
open(MAIL, "| /usr/bin/mail vendedor\@compushop.com.br")
# selecionando o pipe MAIL como saída padrão
select(MAIL);
# enviando a mensagem
print <<"PEDIDO";
Date: $data
To: vendedor\@compushop.com.br
Subject: Pedido de Compra
Produto: $conteudo{produto}
Nome: $conteudo{comprador}
Telefone: $conteudo{fone}
Endereço: $conteudo{endereco}
Cartão de Crédito: $conteudo{cartao}
Número do Cartão: $conteudo{numero}
Validade do Cartão: $conteudo{validade}
PEDIDO
close(MAIL);
Cookies proveêm um mecanismo que permite a um servidor HTTP enviar
informação para um browser, que por sua vez poderá armazenar ou não esta
informação na máquina cliente. Todo cookie possui nome, valor e um servidor
associado a ele. Podemos manipular (enviar, receber, processar, alterar e
remover) cookies usando javascript ou programas CGI. Explicaremos a seguir
como manipular cookies através de programas CGI.
2.6 Cookies
Ao usar um editor de texto que permita acentuação para criar um página,
corremos o risco dos acentos não serem interpretados corretamente por alguns
browsers, em especial browsers instalados em países onde não se utiliza
acentuação, como os Estados Unidos, por exemplo. Se quisermos garantir que a
acentuação da nossa página vai ser universalmente entendida devemos usar as
entities. Nas entities faz diferença usar caracteres maiúsculos
ou minúsculos. Na verdade entities é o único caso onde a HTML é
case-sensitive. É verdade que é muito trabalhoso colocar as
entities ao invés de usar diretamente os caracteres acentuados, mas
alguns editores (como o emacs, por exemplo) permitem que digitemos os
caracteres acentuados e eles se encarregam de convertê-los para as
entities correspondentes. A tabela abaixo especifica as entities
usadas para conseguir letras acentuadas, e alguns caracteres especiais como c
cedilha, símbolo de copyright, caracteres nórdicos, etc.
Apêndice 1: Tabela de Acentos e Caracteres
Especiais
Á Á
È È
ô ô
Ç Ç
á á
è è
Ò Ò
ç ç
 Â
Ë Ë
ò ò
â â
ë ë
Ø Ø
Ñ Ñ
À À
Ð Ð
ø ø
ñ ñ
à à
ð ð
Õ Õ
Å Å
õ õ
Ý Ý
å å
Í Í
Ö Ö
ý ý
à Ã
í í
ö ö
ã ã
Î Î
" "
Ä Ä
î î
Ú Ú
< <
ä ä
Ì Ì
ú ú
> >
Æ Æ
ì ì
Û Û
& &
æ æ
Ï Ï
û û
ï ï
Ù Ù
® ®
É É
ù ù
© ©
é é
Ó Ó
Ü Ü
Þ Þ
Ê Ê
ó ó
ü ü
þ þ
ê ê
Ô Ô
ß ß
Apêndice 2: Tabela ASCII HTML
É possível conseguir acentuação, os caracteres especiais já vistos e ainda
outros usando o código ASCII precedido de &#. A tabela a
seguir mostra os códigos e o caracteres correspondentes.
! !
A A
a a
£ £
à Ã
ã ã
" "
B B
b b
¤ ¤
Ä Ä
ä ä
# #
C C
c c
¥ ¥
Å Å
å å
$ $
D D
d d
¦ ¦
Æ Æ
æ æ
% %
E E
e e
§ §
Ç Ç
ç ç
& &
F F
f f
¨ ¨
È È
è è
' '
G G
g g
© ©
É É
é é
( (
H H
h h
ª ª
Ê Ê
ê ê
) )
I I
i i
« «
Ë Ë
ë ë
* *
J J
j j
¬ ¬
Ì Ì
ì ì
+ +
K K
k k
­
Í Í
í í
, ,
L L
l l
® ®
Î Î
î î
- -
M M
m m
¯ ¯
Ï Ï
ï ï
. .
N N
n n
° °
Ð Ð
ð ð
/ /
O O
o o
± ±
Ñ Ñ
ñ ñ
0 0
P P
p p
² ²
Ò Ò
ò ò
1 1
Q Q
q q
³ ³
Ó Ó
ó ó
2 2
R R
r r
´ ´
Ô Ô
ô ô
3 3
S S
s s
µ µ
Õ Õ
õ õ
4 4
T T
t t
¶ ¶
Ö Ö
ö ö
5 5
U U
u u
· ·
× ×
÷ ÷
6 6
V V
v v
¸ ¸
Ø Ø
ø ø
7 7
W W
w w
¹ ¹
Ù Ù
ù ù
8 8
X X
x x
º º
Ú Ú
ú ú
9 9
Y Y
y y
» »
Û Û
û û
: :
Z Z
z z
¼ ¼
Ü Ü
ü ü
; ;
[ [
{ {
½ ½
Ý Ý
ý ý
< <
\ \
| |
¾ ¾
Þ Þ
þ þ
= =
] ]
} }
¿ ¿
ß ß
ÿ ÿ
> >
^ ^
~ ~
À À
à à
Ā Ā
? ?
_ _
¡ ¡
Á Á
á á
@ @
` `
¢ ¢
 Â
â â